[CloudNeta] EKS 워크샵 스터디 (2) - EKS Network Part 1 - VPC CNI와 파드 네트워킹
이번 게시글에서는 EKS 워크샵 스터디 제 2주차 내용을 작성합니다.
이번 주에는 EKS 네트워킹을 관장하는 플러그인인 VPC CNI에 대해 살펴보며, 네트워크 주소 관리의 내부 로직 살펴보기 및 쿠버네티스 클러스터의 기본인 노드간 통신, 파드간 통신 과정을 배운 후 외부 통신을 실습합니다.
이 글은 3부로 나누어집니다.
- VPC CNI의 동작 원리와 구성요소
- 노드와 파드의 네트워크 구조 (ENI, veth pair, ip rule/route)
- iptables NAT 체인을 통한 파드의 외부 통신 흐름
CNI에 대해
아시다시피 쿠버네티스는 워크로드 관리 대신 네트워크, 스토리지(CSI) 그리고 컨테이너 런타임(CRI)은 플러그인으로 세분화되어 있습니다.
이 중 CNI(Container Network Interface)는 파드가 생성/삭제될 때 네트워크를 어떻게 연결하고 해제할지를 정의하는 표준 스펙입니다. kubelet이 파드를 만들면 CNI 플러그인의 ADD를 호출해 네트워크를 붙이고, 파드가 사라지면 DEL로 정리하는 구조죠.
어떤 CNI 플러그인을 쓰느냐에 따라 파드 네트워킹의 동작 방식이 완전히 달라집니다. Calico는 BGP 기반 라우팅, Cilium은 eBPF 기반, Flannel은 오버레이 네트워크를 사용하는 식입니다. EKS에서는 AWS VPC CNI를 기본으로 사용하며, 이것이 다른 CNI들과 결정적으로 다른 점은 파드에 VPC 내의 실제 ENI 보조 IP를 직접 할당한다는 것입니다. 오버레이 없이 VPC 네이티브 통신이 가능하다는 뜻이죠.
AWS의 CNI는?
AWS에서 네이티브로 활용하기 위해 고안된 AWS VPC라는 CNI를 사용합니다. 이는 EKS 클러스터의 기본 네트워킹 애드온으로, 파드에 VPC 네트워크의 실제 IP를 직접 할당합니다. 파드의 IP 네트워크 대역과 노드의 IP대역이 같으므로, 직접 통신할 수도 있습니다.
CNI는 두 구성요소로 이루어집니다. CNI 바이너리(pod to pod 네트워크를 설정) + ipamd(IP 주소 관리)로 구성되며, ENI와 IP의 **웜 풀(pre-allocation)**을 유지해 빠른 파드 시작을 지원합니다.
- 서브넷: 클러스터 생성 시 2개 이상의 AZ에 서브넷을 지정하고, 배포 전 서브넷의 가용 IP 수를 반드시 확인
- IP 모드 선택:
- 보조 IP 모드(기본값) - 소규모 클러스터에 적합. 파드 수는 인스턴스 유형의 ENI 수 x ENI당 IP 수로 제한됨
- 접두사 모드(Prefix Mode) - 파드 밀도가 부족할 때 사용. ENI에 /28 접두사를 할당해 노드당 파드 수를 대폭 증가
- 파드 보안 그룹: 기본적으로 노드의 보안 그룹이 파드에 적용됨. 파드별로 다른 네트워크 규칙이 필요하면 Security Groups for Pods 활성화
- 사용자 지정 네트워킹(Custom Networking): IPv4 주소 고갈 시 보조 CIDR(예:
100.64.0.0/10,198.19.0.0/16)을 할당하여 파드 전용 서브넷을 분리 → RFC1918 IP 소모 방지 - VPC 통합: VPC Flow Logs, 라우팅 정책, 보안 그룹을 그대로 활용 가능
CNI의 IP 할당방안 학습
IP 슬롯 확인 로직
새로운 파드가 생성되어 IP 슬롯이 필요할 때, VPC CNI(ipamd)는 아래 플로우를 따릅니다.
%%{ init: { "flowchart": { "curve": "linear" } } }%%
flowchart LR
A["🔵 새 슬롯 필요"] --> B{"Primary ENI에
빈 슬롯 있는가?"}
B -- "Yes" --> F["파드에 슬롯 할당"]
B -- "No" --> C{"Secondary ENI 존재?
WARM_ENI_TARGET
WARM_IP_TARGET
MINIMUM_IP_POOL"}
C -- "Yes" --> E{"Secondary ENI에
빈 슬롯 있는가?"}
C -- "No" --> D{"인스턴스에 새 ENI
부착 가능한가?"}
D -- "Yes" --> G["새 ENI 부착"] --> E
D -- "No" --> H["🔴 실패"]
E --> F --> I["🟢 성공"]
- Primary ENI에 빈 슬롯이 있으면 바로 할당
- 없으면 Secondary ENI가 존재하는지 확인
(WARM_ENI_TARGET,WARM_IP_TARGET,MINIMUM_IP_POOL설정 기반) - Secondary ENI가 없으면 인스턴스에 새 ENI를 붙일 여유가 있는지 확인
- 여유가 있으면 ENI를 부착 → 슬롯 할당 → Success
- 인스턴스 ENI 한도 초과 시 → Failure (파드가 스케줄링 불가)
파드에 IP를 할당하는 방법 3가지
파드에 IP를 할당하는 방법은 총 3가지가 있습니다.
- 보조 IP 부여(Secondary IPv4 Address): 인스턴스 유형에 최대 ENI 갯수와 할당 가능 IP 수[1]를 조합하여 선정하는 방식
- 접두사 위임(Prefix Delegation): IPv4 28bit 서브넷(prefix)를 위임하여 할당 가능 IP 수와 인스턴스 유형에 권장하는 최대 갯수로 선정하는 방식
- AWS VPC CNI Custom Networking: 노드와 파드대역 분리, 파드에 별도 서브넷을 부여한 후 사용 (공식 문서)

기본적으로 노드와 파드는 같은 서브넷에서 IP를 받습니다. Custom Networking은 이를 분리합니다:
- 노드(Primary ENI) → 기존 VPC 서브넷 (예:
10.0.0.0/16) - 파드(Secondary ENI) → 별도 서브넷 (예:
100.64.0.0/10CG-NAT 대역)
언제 필요한가?
- RFC1918 IPv4 주소가 고갈되었을 때 (대규모 클러스터, 1000개 이상 파드 운용 시)
- 파드에 노드와 다른 보안 그룹/네트워크 정책을 적용해야 할 때
- 여러 EKS 클러스터 + 온프레미스 연동 시 CIDR 충돌을 피하고 싶을 때
주의사항
- 활성화 후 기존 노드에는 적용되지 않음 → 노드를 drain & 재배포해야 함
- IPv6 전환이 가능하다면 Custom Networking 대신 IPv6 클러스터를 권장 (AWS 공식 입장)
- CIDR이 겹치는(overlapping) 문제는 Custom Networking으로 해결 불가
→ Private NAT Gateway 사용
이번 스터디에서는 직접 실습하지 않지만, 실무에서 대규모 운영 시 고려해야 하는 옵션입니다.
실습환경 준비하기 - EKS 배포
2주차의 내용도 마찬가지로 아래 링크에서 살펴보실 수 있습니다.
배포 이후 네트워크 현황 살펴보기
그럼 배포이후 네트워크 현황을 보시죠. 위 코드를 배포한 후, ENI IP 를 살펴봅시다.
사전작업을 위해 실습에 필요한 PEM키를 ~/.ssh 디렉터리에 복사하는 것을 권장합니다.
(준비과정) - 노드 접속 및 IP주소 관리하기
# 공인 IP주소를 확인하고
aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
-----------------------------------------------------------------------
| DescribeInstances |
+-----------------------+---------------+------------------+----------+
| InstanceName | PrivateIPAdd | PublicIPAdd | Status |
+-----------------------+---------------+------------------+----------+
| myeks-1nd-node-group | 192.168.4.44 | x.x.x.x | running |
| myeks-1nd-node-group | 192.168.1.58 | x.x.x.x | running |
| myeks-1nd-node-group | 192.168.9.33 | x.x.x.x | running |
+-----------------------+---------------+------------------+----------+
# 공인 IP주소를 쉘 변수로 등록하고
NODE1="IP주소"
NODE2="IP주소"
NODE3="IP주소"
# shell로 편히 붙을 수 있게 준비합니다.
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh -o StrictHostKeyChecking=no ec2-user@$i hostname; echo; done
>> node [REDACTED] <<
Warning: Permanently added '[REDACTED]' (ED25519) to the list of known hosts.
ip-192-168-4-44.ap-northeast-2.compute.internal
>> node [REDACTED] <<
Warning: Permanently added '[REDACTED]' (ED25519) to the list of known hosts.
ip-192-168-1-58.ap-northeast-2.compute.internal
>> node [REDACTED] <<
Warning: Permanently added '[REDACTED]' (ED25519) to the list of known hosts.
ip-192-168-9-33.ap-northeast-2.compute.internal
# 이후엔 단순히 이렇게 붙습니다.
ssh $NODE1
ssh $NODE2
ssh $NODE3
네트워크 기본 정보 살펴보기
로컬 PC에서 파드 상세 정보를 확인합니다. 저는 mise를 사용하여 kubeconfig 설정을 별도로 처리하였습니다.
VPC CNI가 정상적으로 도는지 확인해보겠습니다.
VPC CNI 구동여부 확인해보기
$ mise run myeks
[aws-sts] 캐시된 토큰 사용 (51분 남음)
[aws-sts] 캐시된 토큰 사용 (51분 남음)
[myeks] $ aws eks update-kubeconfig --region ap-northeast-2 --name myeks
Updated context arn:aws:eks:ap-northeast-2:<REDACTED>:cluster/myeks in /home/s3ich4n/.kube/config
[aws-sts] 캐시된 토큰 사용 (51분 남음)
$ k get daemonset aws-node -n kube-system -owide
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
aws-node 3 3 3 3 3 <none> 43m aws-node,aws-eks-nodeagent 602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/amazon-k8s-cni:v1.21.1-eksbuild.5,602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/amazon/aws-network-policy-agent:v1.3.1-eksbuild.1 k8s-app=aws-node
aws-node의 DaemonSet 상태를 확인해보면, 워커 노드 3대 모두에 AWS VPC CNI가 정상 배포된 것을 볼 수 있습니다. Desired, Current, Available 값이 모두 3, Pods Status도 3 Running / 0 Failed
또한 WARM_ENI_TARGET=1이 적용되어 여유 ENI 1개를 유지하도록 설정된 것도 확인할 수 있습니다.
$ k describe daemonset aws-node --namespace kube-system
...
Desired Number of Nodes Scheduled: 3
Current Number of Nodes Scheduled: 3
Number of Nodes Scheduled with Available Pods: 3
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Containers:
aws-node:
Image: .../amazon-k8s-cni:v1.21.1-eksbuild.5
Environment:
CLUSTER_NAME: myeks
WARM_ENI_TARGET: 1
...
환경변수 값도 확인해보죠.
$ k get ds aws-node -n kube-system -o json | jq '.spec.template.spec.containers[0].env'
[
{
"name": "ADDITIONAL_ENI_TAGS",
"value": "{}"
},
{
"name": "ANNOTATE_POD_IP",
"value": "false"
},
{
"name": "AWS_VPC_CNI_NODE_PORT_SUPPORT",
"value": "true"
},
이후 kube-proxy의 설정을 조회하여 iptables 모드를 기본적으로 사용하는지 조회해봅시다. 그리고 iptables의 설정은 어떤지도 함께 살펴봅시다.
iptables 모드를 살펴보는 이유$ k describe cm -n kube-system kube-proxy-config
...
iptables: # iptables 설정
masqueradeAll: false
masqueradeBit: 14
minSyncPeriod: 0s
syncPeriod: 30s
...
mode: "iptables" # 사용중인 모드 확인
배포현황 살펴보기
노드의 IP와 파드의 IP, 이름 그리고 갯수도 확인해봅시다.
$ aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
-----------------------------------------------------------------------
| DescribeInstances |
+-----------------------+---------------+------------------+----------+
| InstanceName | PrivateIPAdd | PublicIPAdd | Status |
+-----------------------+---------------+------------------+----------+
| myeks-1nd-node-group | 192.168.4.44 | <REDACTED> | running |
| myeks-1nd-node-group | 192.168.1.58 | <REDACTED> | running |
| myeks-1nd-node-group | 192.168.9.33 | <REDACTED> | running |
+-----------------------+---------------+------------------+----------+
# ip 주소와
$ k get pod -n kube-system -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,STATUS:.status.phase
NAME IP STATUS
aws-node-cx5xs 192.168.4.44 Running
aws-node-kj5th 192.168.1.58 Running
aws-node-vwxmb 192.168.9.33 Running
coredns-d487b6fcb-74fwp 192.168.10.233 Running
coredns-d487b6fcb-pkb2g 192.168.2.141 Running
kube-proxy-4twtv 192.168.9.33 Running
kube-proxy-gxqzj 192.168.4.44 Running
kube-proxy-xvf6v 192.168.1.58 Running
# 이름과 갯수도 세어봅시다.
$ kubectl get pod -A -o name
pod/aws-node-cx5xs
pod/aws-node-kj5th
pod/aws-node-vwxmb
pod/coredns-d487b6fcb-74fwp
pod/coredns-d487b6fcb-pkb2g
pod/kube-proxy-4twtv
pod/kube-proxy-gxqzj
pod/kube-proxy-xvf6v
$ kubectl get pod -A -o name | wc -l
8
기본 네트워크 구성 살펴보기 - 워커노드 1
이번에는 워커 노드 하나의 구성을 통해 네트워크의 네임스페이스와, 파드의 네트워크 옵션에 따른 사항을 기록합니다.
호스트 네트워크 vs 파드 네트워크
hostNetwork 옵션을 확인해보면, 어떤 파드가 호스트의 네트워크 네임스페이스를 공유하는지 알 수 있습니다.
$ kubectl get pod -A -o custom-columns=NAME:.metadata.name,IP:.status.podIP,HOST_NET:.spec.hostNetwork
NAME IP HOST_NET
aws-node-cx5xs 192.168.4.44 true
aws-node-kj5th 192.168.1.58 true
aws-node-vwxmb 192.168.9.33 true
coredns-d487b6fcb-74fwp 192.168.10.233 <none>
coredns-d487b6fcb-pkb2g 192.168.2.141 <none>
kube-proxy-4twtv 192.168.9.33 true
kube-proxy-gxqzj 192.168.4.44 true
kube-proxy-xvf6v 192.168.1.58 true
aws-node,kube-proxy→hostNetwork: true- 노드 IP를 그대로 사용. 별도 네트워크 네임스페이스를 만들지 않고 호스트의 Root netns를 공유coredns→<none>(=false) - 파드 전용 netns가 생성되고, VPC CNI가 보조 IP를 할당
네트워크 네임스페이스 확인
Node 2에서 lsns로 네트워크 네임스페이스를 확인하면:
$ ssh ec2-user@$NODE2 sudo lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 111 1 root unassigned /usr/lib/systemd/systemd ...
4026532210 net 2 4012 65535 0 /run/netns/cni-4b26bdc7-4acf-3382-3847-ec6cd4ab3cd5 /pause
- 첫 번째 줄 - Root(호스트) netns. PID 1(systemd)을 포함한 111개 프로세스가 공유.
hostNetwork: true인 aws-node, kube-proxy도 여기에 속함 - 두 번째 줄 - coredns 파드 전용 netns.
/run/netns/cni-4b26bdc7-...경로로 격리됨./pause컨테이너가 이 netns를 유지하고, coredns 컨테이너가 이를 공유
veth pair 확인
coredns 파드의 네트워크 네임스페이스에 직접 진입해서 인터페이스를 확인하면:
$ ssh ec2-user@$NODE2 sudo nsenter -t $(pgrep -o coredns) -n ip -br -c link
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0@if3 UP 26:0e:98:a6:5d:e6 <BROADCAST,MULTICAST,UP,LOWER_UP>
파드 안에서는 eth0@if3이 보이고, 호스트에서는 eniaa9a601f849@if3이 보입니다. 이 둘이 veth pair로 연결되어 있는 것입니다:
[파드 netns] eth0@if3 ←── veth pair ──→ eniaa9a601f849@if3 [Root netns]
↓
ens5 (Primary ENI) → VPC
ENI별 보조 IP 할당 현황
AWS 콘솔(EC2 → 인스턴스 → 네트워킹 탭)에서 각 노드의 ENI와 보조 IP를 확인해봅시다.
Node 1 (파드 미배포):
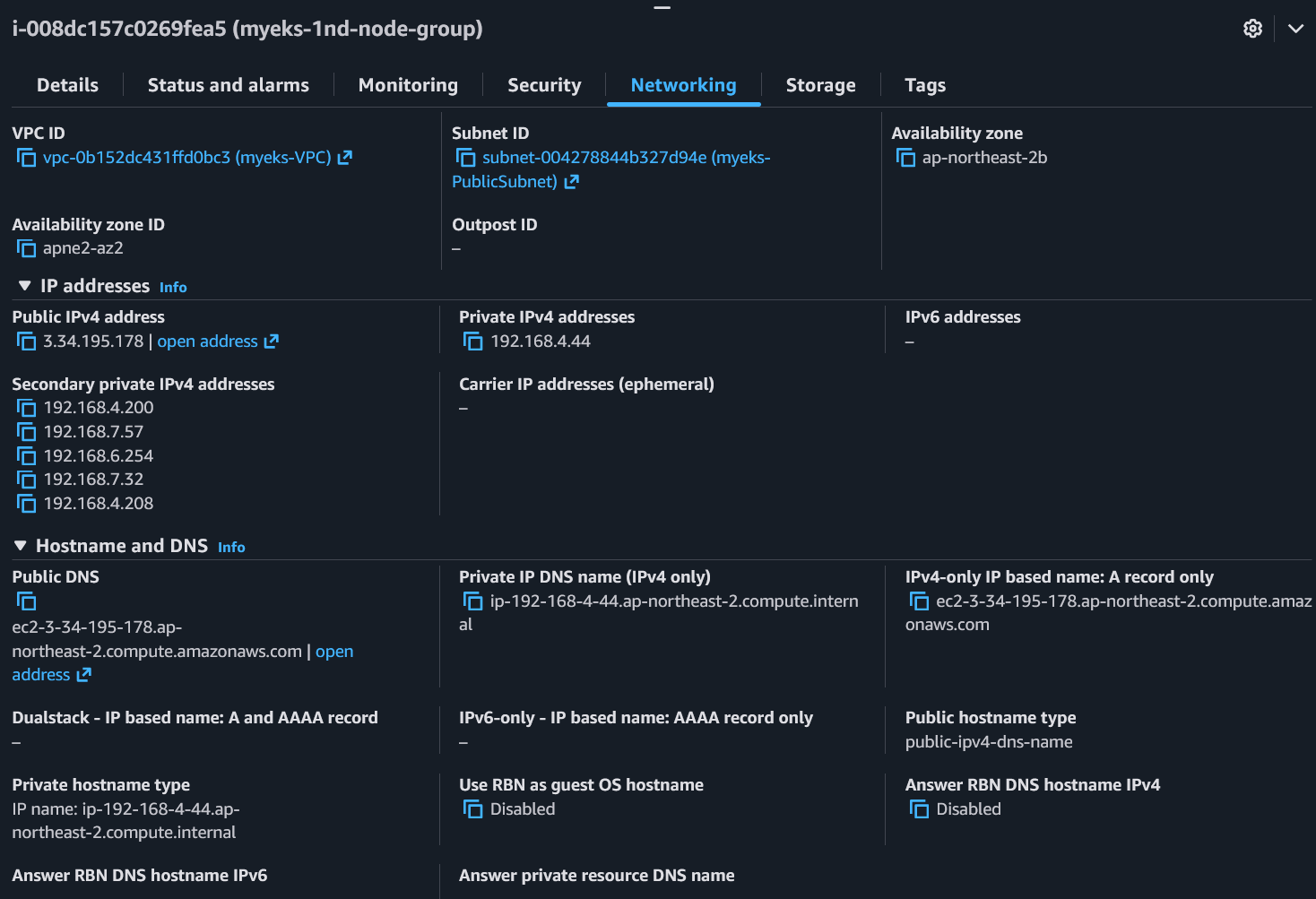
- Private IPv4:
192.168.4.44(Primary ENI 자체 IP) - Secondary private IPv4: 5개 - Primary ENI의 보조 IP
- ENI 1개, 총 6개 IP (1 + 5)
Node 2 (coredns 배포됨):
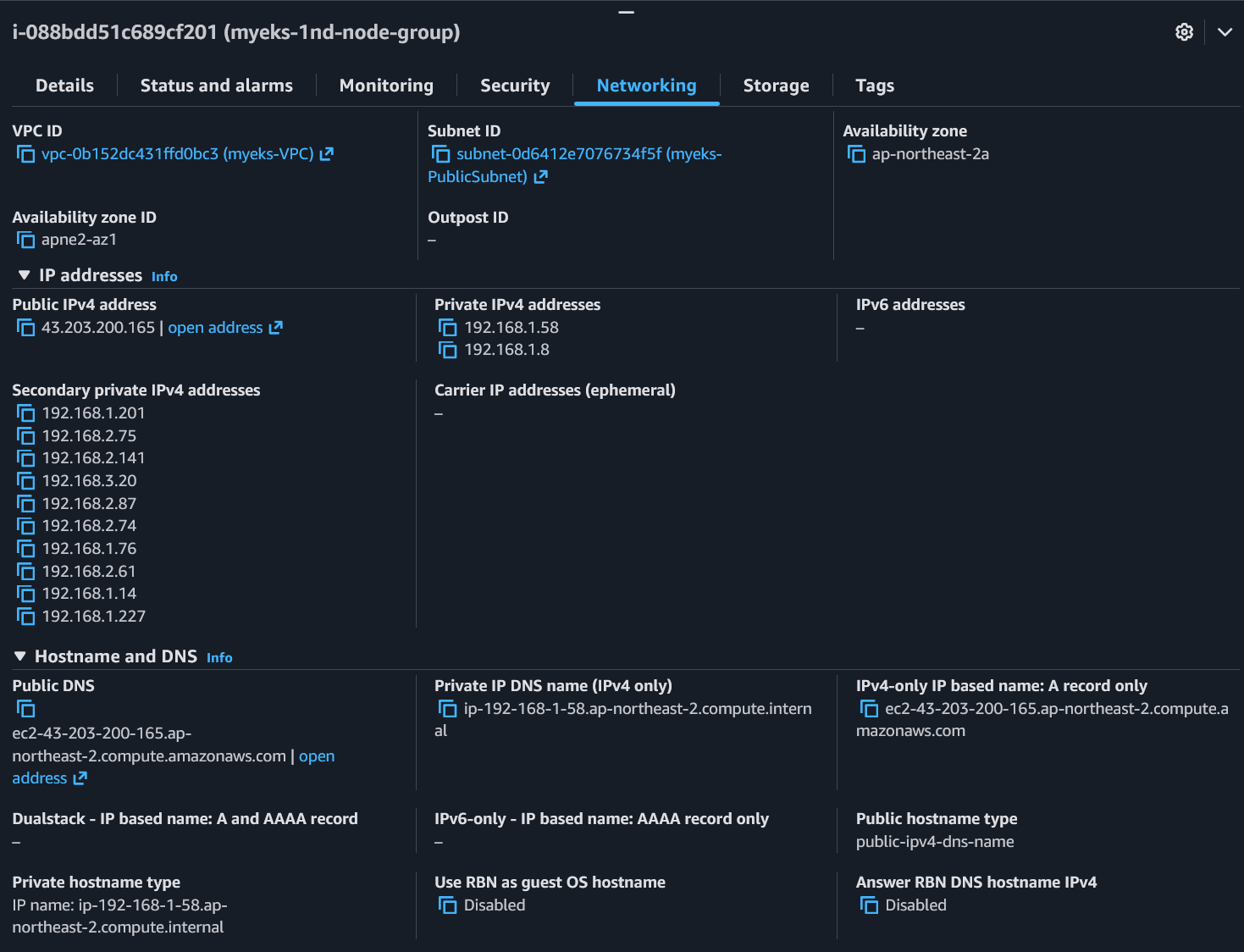
- Private IPv4:
192.168.1.58(Primary ENI),192.168.1.8(Secondary ENI) - 2개 - Secondary private IPv4: 10개 - ENI당 5개씩
- ENI 2개, 총 12개 IP (2 + 10)
WARM_ENI_TARGET=1 설정 때문입니다. 이 설정은 "항상 여유 ENI 1개를 예비로 유지하라"는 뜻입니다.
| 노드 | 파드 유무 | ENI 수 | IP 구성 | 이유 |
|---|---|---|---|---|
| Node 1 | 없음 | 1 (Primary만) | 1 + 5 = 6개 | 파드가 없으므로 Secondary ENI 불필요 |
| Node 2 | coredns 1개 | 2 (Primary + Secondary) | 2 + 10 = 12개 | 파드 할당으로 Primary ENI의 IP 소모 → 여유 ENI 1개 자동 부착 |
t3.medium은 ENI당 최대 6개 IP(자체 1 + 보조 5)를 가질 수 있습니다. 파드가 배포되면 ipamd가 WARM_ENI_TARGET=1을 충족하기 위해 Secondary ENI를 부착하고, 거기에도 보조 IP 5개를 미리 확보해둡니다. 앞서 ipamd.log에서 본 total IPs: 5 → 10 변화가 바로 이 과정입니다.
CNI 로그 확인
각 노드의 /var/log/aws-routed-eni 디렉터리에는 VPC CNI 구성요소별 로그가 저장됩니다.
# CNI 로그 디렉터리 확인
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i tree /var/log/aws-routed-eni; echo; done
# plugin.log 확인 (CNI 바이너리 호출 로그)
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo cat /var/log/aws-routed-eni/plugin.log | jq '.msg'; echo; done
# ipamd.log 확인 (IP 주소 관리 데몬 로그)
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo cat /var/log/aws-routed-eni/ipamd.log | jq '.msg'; echo; done
로그 디렉터리를 확인하면 아래와 같은 파일들이 존재합니다:
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i tree /var/log/aws-routed-eni; echo; done
>> node1 <<
/var/log/aws-routed-eni
├── ebpf-sdk.log
├── ipamd.log
└── network-policy-agent.log # plugin.log 없음!
>> node2 <<
/var/log/aws-routed-eni
├── ebpf-sdk.log
├── egress-v6-plugin.log
├── ipamd.log
├── network-policy-agent.log
└── plugin.log
>> node3 <<
/var/log/aws-routed-eni
├── ebpf-sdk.log
├── egress-v6-plugin.log
├── ipamd.log
├── network-policy-agent.log
└── plugin.log
| 파일 | 담당 구성요소 | 설명 |
|---|---|---|
ipamd.log |
L-IPAMD | ENI 부착/해제, IP 웜 풀 관리, 파드에 IP 할당/회수 |
plugin.log |
CNI 바이너리 | kubelet이 파드 생성/삭제 시 호출하는 CNI ADD/DEL 실행 로그 |
network-policy-agent.log |
Network Policy Agent | eBPF 기반 NetworkPolicy 적용 로그 |
ebpf-sdk.log |
eBPF SDK | Network Policy Agent가 사용하는 eBPF 프로그램 로드/관리 |
egress-v6-plugin.log |
Egress v6 Plugin | IPv6 이그레스 트래픽 처리 |
plugin.log이 없다?
coredns 등 사용자 파드가 스케줄링되지 않은 노드에서는 CNI ADD가 호출된 적이 없으므로 plugin.log 자체가 생성되지 않습니다.
- plugin.log에서 읽는 파드 IP 할당 과정
plugin.log를 보면 파드 하나가 IP를 받는 전체 과정이 순서대로 기록되어 있습니다. Node 2의 coredns 파드 할당 로그를 발췌하면:
# CNI add 요청 수신
"Received CNI add request: ContainerID(9078cfa6...) Netns(/var/run/netns/cni-4b26bdc7-...)
IfName(eth0) Args(K8S_POD_NAMESPACE=kube-system;K8S_POD_NAME=coredns-d487b6fcb-pkb2g)"
# MTU 설정 (AWS 점보 프레임)
"MTU value set is 9001:"
# ipamd로부터 IP 할당 응답
"Received add network response from ipamd ...
Success:true IPAllocationMetadata:{IPv4Addr:\"192.168.2.141\" RouteTableId:254}
VPCv4CIDRs:\"192.168.0.0/16\""
# veth pair 생성 + 라우트 설정
"SetupPodNetwork: hostVethName=eniaa9a601f849, contVethName=eth0,
netnsPath=/var/run/netns/cni-4b26bdc7-..., ipAddr=192.168.2.141/32, mtu=9001"
"Successfully setup container route, containerAddr=192.168.2.141/32, hostVeth=eniaa9a601f849"
"Successfully setup toContainer rule, containerAddr=192.168.2.141/32"
# 네트워크 정책 적용
"Network Policy agent for EnforceNpToPod returned Success : true"
정리하면 이런 흐름입니다:
| 순서 | 로그 핵심 | 의미 |
|---|---|---|
| 1 | Received CNI add request |
kubelet이 파드 생성 → CNI 바이너리 호출 |
| 2 | MTU value set is 9001 |
AWS 점보 프레임 기본값 적용 |
| 3 | Received add network response from ipamd → IPv4Addr:"192.168.2.141" |
ipamd 웜 풀에서 IP 할당 |
| 4 | SetupPodNetwork: hostVethName=eniaa9a601f849, contVethName=eth0 |
veth pair 생성 (호스트 eniXXX ↔ 컨테이너 eth0) |
| 5 | Successfully setup container route, containerAddr=192.168.2.141/32 |
파드 IP에 /32 호스트 라우트 설정 |
| 6 | Network Policy agent ... returned Success |
eBPF 네트워크 정책 적용 완료 |
위 플로우를 보면, 앞서 살펴본 "IP 슬롯 확인 로직"이 실제로 동작하는 것을 확인할 수 있습니다. ipamd가 웜 풀에서 IP를 꺼내주고 → CNI 바이너리가 veth pair + 라우트를 세팅하는 구조입니다.
ipamd.log: 웜 풀 관리 로그
ipamd.log는 양이 매우 방대하므로 핵심 키워드만 필터링해서 살펴봅니다. Node 2(coredns 배포됨)의 로그를 시간순으로 추리면:
# 1) 초기화 - 웜 풀 설정값 로드
"Using WARM_ENI_TARGET 1"
"Using WARM_PREFIX_TARGET 1"
# 2) Primary ENI에 보조 IP 5개 할당 (maxIPsPerENI = 5)
"Total IPs/Prefixes = 0/0, AssignedIPs/CooldownIPs: 0/0"
"Found ENI eni-0075d3f9... cur=0, max=5"
"Allocated 5 private IP addresses"
"Total IPs/Prefixes = 5/0, AssignedIPs/CooldownIPs: 0/0"
# 3) IP pool manager 설정 확인
"max pods: 17, warm IP target: 0, warm prefix target: 1, warm ENI target: 1"
# 4) coredns 파드에 IP 할당
"AssignPodIPv4Address: IP address pool stats: total 5, assigned 0"
"Assigned IP from network card: 0 -> IPv4: 192.168.2.141"
"Total IPs/Prefixes = 5/0, AssignedIPs/CooldownIPs: 1/0"
# 5) WARM_ENI_TARGET=1 충족을 위해 Secondary ENI 부착 → IP 5개 추가
"total IPs: 10, assigned IPs: 1" ← 최종 상태
흐름을 정리하면:
| 단계 | total IPs | assigned IPs | 무슨 일이? |
|---|---|---|---|
| 초기화 | 0 | 0 | ipamd 시작, 웜 풀 비어있음 |
| Primary ENI 세팅 | 5 | 0 | ENI당 max 5개 보조 IP 할당 |
| 파드 배포 | 5 | 1 | coredns에 192.168.2.141 할당 |
| Secondary ENI 부착 | 10 | 1 | WARM_ENI_TARGET=1 충족 위해 여유 ENI 추가 |
Node 1(파드 미배포)은 total: 5, assigned: 0에서 변화 없이 유지됩니다 - Primary ENI의 보조 IP만 확보해둔 상태입니다.
현재 네트워크 정보 살펴보기
이어서 각 노드의 네트워크 인터페이스와 라우팅 테이블을 확인해봅시다.
# 네트워크 인터페이스 확인
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c addr; echo; done
# 라우팅 테이블 확인
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c route; echo; done
- 네트워크 인터페이스 비교
Node 1 (파드 미배포):
2: ens5: inet 192.168.4.44/22 ← Primary ENI (노드 IP)
Node 2 (coredns 배포됨):
2: ens5: inet 192.168.1.58/22 ← Primary ENI (노드 IP)
3: eniaa9a601f849@if3: ← 파드 veth pair (호스트 측)
link-netns cni-4b26bdc7-...
4: ens6: inet 192.168.1.8/22 ← Secondary ENI (웜 풀용)
Node 3 (coredns 배포됨):
2: ens5: inet 192.168.9.33/22 ← Primary ENI (노드 IP)
3: enidc82c4d90e6@if3: ← 파드 veth pair (호스트 측)
link-netns cni-20479334-...
4: ens6: inet 192.168.8.200/22 ← Secondary ENI (웜 풀용)
파드가 배포된 Node 2, 3에는 인터페이스가 3종류 보입니다:
| 인터페이스 | 역할 | 비고 |
|---|---|---|
ens5 |
Primary ENI | 노드 자체 IP, 외부 통신용 |
ens6 |
Secondary ENI | WARM_ENI_TARGET=1 설정으로 미리 부착된 여유 ENI |
eniXXX@if3 |
veth pair (호스트 측) | 파드 네트워크 네임스페이스와 연결. link-netns cni-...로 확인 가능 |
반면 Node 1은 파드가 없으므로 ens5(Primary ENI)만 존재합니다.
모든 인터페이스의 MTU가 9001입니다. AWS VPC 내에서 점보 프레임을 기본 지원하기 때문이며, 파드의 veth pair에도 동일하게 적용됩니다.
- 라우팅 테이블 비교
Node 1 (파드 없음): 기본 라우트만 존재
default via 192.168.4.1 dev ens5
192.168.4.0/22 dev ens5 proto kernel scope link src 192.168.4.44
Node 2 (coredns IP: 192.168.2.141):
default via 192.168.0.1 dev ens5
192.168.0.0/22 dev ens5 proto kernel scope link src 192.168.1.58
192.168.2.141 dev eniaa9a601f849 scope link ← 파드 IP → veth pair로 향하는 /32 호스트 라우트
Node 3 (coredns IP: 192.168.10.233):
default via 192.168.8.1 dev ens5
192.168.8.0/22 dev ens5 proto kernel scope link src 192.168.9.33
192.168.10.233 dev enidc82c4d90e6 scope link ← 파드 IP → veth pair로 향하는 /32 호스트 라우트
핵심은 마지막 줄입니다. 파드 IP(192.168.2.141, 192.168.10.233)에 대해 /32 호스트 라우트가 veth pair 디바이스(eniXXX)를 가리키고 있습니다. 이것이 VPC CNI가 파드 트래픽을 처리하는 방식입니다. 노드로 들어온 파드 대상 패킷은 이 라우트를 통해 해당 파드의 네트워크 네임스페이스로 전달됩니다.
iptables NAT 규칙 살펴보기
노드의 iptables -t nat 규칙을 보면, kube-proxy가 Service ClusterIP → 파드 IP로의 DNAT[2] 규칙을 관리하고, VPC CNI가 외부 통신을 위한 SNAT[3] 규칙을 관리하는 것을 확인할 수 있습니다. 각 체인의 상세 역할과 패킷 흐름은 iptables NAT 체인 정리를 참고하세요.
iptables -t nat -S (전체 규칙)
$ ssh ec2-user@$NODE1 sudo iptables -t nat -S
# === AWS VPC CNI가 관리하는 체인 ===
# VPC CIDR(192.168.0.0/16) 내부 통신은 SNAT 하지 않음
-A AWS-SNAT-CHAIN-0 -d 192.168.0.0/16 -j RETURN
# VPC 외부로 나가는 트래픽은 노드 IP로 SNAT
-A AWS-SNAT-CHAIN-0 ! -o vlan+ -m addrtype ! --dst-type LOCAL -j SNAT --to-source 192.168.4.44
# === kube-proxy가 관리하는 체인 ===
# Service ClusterIP → KUBE-SVC 체인으로 분기
-A KUBE-SERVICES -d 10.100.0.1/32 -p tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -d 10.100.0.10/32 -p udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SERVICES -d 10.100.0.10/32 -p tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
# KUBE-SVC → KUBE-SEP (Service Endpoint) 체인으로 로드밸런싱
# coredns 2개 파드에 50%씩 분배
-A KUBE-SVC-TCOU7JCQXEZGVUNU --probability 0.5 -j KUBE-SEP-A66D6VN7ZJSNMAM6
-A KUBE-SVC-TCOU7JCQXEZGVUNU -j KUBE-SEP-WB6TFUZR7TOT5QYJ
# KUBE-SEP → 실제 파드 IP로 DNAT
-A KUBE-SEP-A66D6VN7ZJSNMAM6 -p udp -j DNAT --to-destination 192.168.10.233:53
-A KUBE-SEP-WB6TFUZR7TOT5QYJ -p udp -j DNAT --to-destination 192.168.2.141:53
# kubernetes API server (2개 endpoint, 50% 분배)
-A KUBE-SEP-Z3ACTWAOMUYSA5G3 -p tcp -j DNAT --to-destination 192.168.1.16:443
-A KUBE-SEP-4JHLU77BNFDRXS33 -p tcp -j DNAT --to-destination 192.168.5.211:443
핵심을 정리하면 아래와 같습니다:
| 체인 | 관리 주체 | 역할 |
|---|---|---|
AWS-SNAT-CHAIN-0 |
VPC CNI | VPC 외부 통신 시 노드 IP로 SNAT. VPC 내부(192.168.0.0/16)는 RETURN |
AWS-CONNMARK-CHAIN-0 |
VPC CNI | 파드에서 나가는 외부 트래픽에 CONNMARK 설정 (응답 패킷 추적용) |
KUBE-SERVICES |
kube-proxy | ClusterIP로 들어온 트래픽을 해당 Service 체인으로 분기 |
KUBE-SVC-* |
kube-proxy | 여러 파드 endpoint에 --probability로 균등 분배 (로드밸런싱) |
KUBE-SEP-* |
kube-proxy | 실제 파드 IP:Port로 DNAT 수행 |
KUBE-MARK-MASQ |
kube-proxy | 헤어핀 트래픽[4]에 masquerade 마킹 |
KUBE-POSTROUTING |
kube-proxy | KUBE-MARK-MASQ로 마킹된 패킷에 MASQUERADE 적용 |
KUBE-NODEPORTS |
kube-proxy | NodePort 타입 Service 트래픽 처리 (현재 규칙 없음) |
KUBE-KUBELET-CANARY |
kubelet | kubelet 활성 상태 확인용 빈 체인[5] |
KUBE-PROXY-CANARY |
kube-proxy | kube-proxy 활성 상태 확인용 빈 체인[5:1] |
테스트용 netshoot 배포하기
먼저 터미널 3개를 띄워서 route table을 watch 해봅시다.
ssh ec2-user@$NODE1
watch -d "ip link | egrep 'ens|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
ssh ec2-user@$NODE2
watch -d "ip link | egrep 'ens|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
ssh ec2-user@$NODE3
watch -d "ip link | egrep 'ens|eni' ;echo;echo "[ROUTE TABLE]"; route -n | grep eni"
이후 로컬 PC에서 netshoot 을 배포합시다. 아래 YAML 파일을 준비합시다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: netshoot-pod
spec:
replicas: 3
selector:
matchLabels:
app: netshoot-pod
template:
metadata:
labels:
app: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: praqma/network-multitool
ports:
- containerPort: 80
- containerPort: 443
env:
- name: HTTP_PORT
value: "80"
- name: HTTPS_PORT
value: "443"
terminationGracePeriodSeconds: 0
배포 후 파드 상태와 IP를 확인합니다.
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
netshoot-pod-64fbf7fb5-5wqnl 1/1 Running 0 39s 192.168.1.201 ip-192-168-1-58...
netshoot-pod-64fbf7fb5-bzvd8 1/1 Running 0 39s 192.168.6.254 ip-192-168-4-44...
netshoot-pod-64fbf7fb5-nd2vz 1/1 Running 0 39s 192.168.9.201 ip-192-168-9-33...
3개 파드가 각 노드에 하나씩 배포되었습니다. 라우팅 테이블도 확인해봅시다.
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c route; echo; done
>> node1 (192.168.4.44) <<
...
192.168.6.254 dev eniacae5529058 scope link ← netshoot 파드
>> node2 (192.168.1.58) <<
...
192.168.1.201 dev enid8dd5b67408 scope link ← netshoot 파드
192.168.2.141 dev eniaa9a601f849 scope link ← coredns 파드
>> node3 (192.168.9.33) <<
...
192.168.9.201 dev eni499eaac00bf scope link ← netshoot 파드
192.168.10.233 dev enidc82c4d90e6 scope link ← coredns 파드
netshoot 파드가 배포되면서 각 노드에 새로운 /32 호스트 라우트가 추가된 것을 확인할 수 있습니다. watch로 모니터링하고 있었다면 아래처럼 라우트가 실시간으로 추가되는 것을 볼 수 있었을 것입니다.
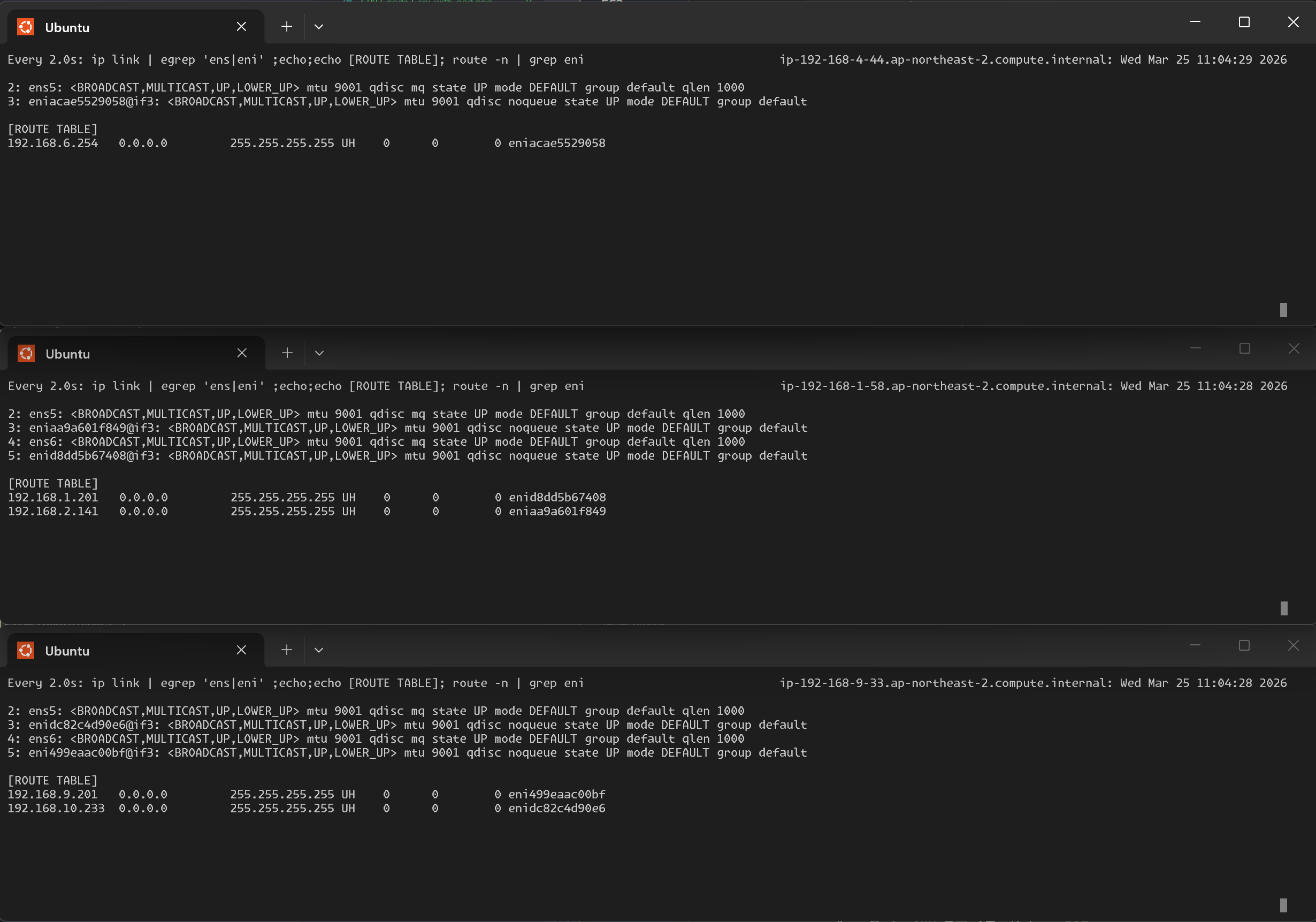
워커노드의 ENI 및 네임스페이스 상세 확인
노드에 원활한 접속 및 로깅 확인을 위해 아래와 같이 파드 이름을 쉘 변수로 지정해둡시다.
# 파드 이름 변수 지정
PODNAME1=$(kubectl get pod -l app=netshoot-pod -o jsonpath='{.items[0].metadata.name}')
PODNAME2=$(kubectl get pod -l app=netshoot-pod -o jsonpath='{.items[1].metadata.name}')
PODNAME3=$(kubectl get pod -l app=netshoot-pod -o jsonpath='{.items[2].metadata.name}')
echo $PODNAME1 $PODNAME2 $PODNAME3
netshoot-pod-64fbf7fb5-5wqnl netshoot-pod-64fbf7fb5-bzvd8 netshoot-pod-64fbf7fb5-nd2vz
Node 3에 SSH 접속하여 인터페이스, 라우팅, 네트워크 네임스페이스를 확인해봅시다.
[ec2-user@ip-192-168-9-33 ~]$ ip -br -c addr show
lo UNKNOWN 127.0.0.1/8
ens5 UP 192.168.9.33/22 ← Primary ENI (노드 IP)
enidc82c4d90e6@if3 UP fe80::... ← coredns veth pair
ens6 UP 192.168.8.200/22 ← Secondary ENI (웜 풀)
eni499eaac00bf@if3 UP fe80::... ← netshoot veth pair
netshoot 배포 전에는 veth pair가 1개(coredns)였지만, 배포 후 eni499eaac00bf가 추가된 것을 확인할 수 있습니다.
라우팅 테이블에서도 파드별 /32 호스트 라우트가 veth pair를 가리킵니다:
[ec2-user@ip-192-168-9-33 ~]$ route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.8.1 0.0.0.0 UG 512 0 0 ens5
192.168.8.0 0.0.0.0 255.255.252.0 U 512 0 0 ens5
192.168.9.201 0.0.0.0 255.255.255.255 UH 0 0 0 eni499eaac00bf
192.168.10.233 0.0.0.0 255.255.255.255 UH 0 0 0 enidc82c4d90e6
네트워크 네임스페이스도 확인하면, coredns와 netshoot 각각 별도의 netns가 생성된 것을 볼 수 있습니다:
[ec2-user@ip-192-168-9-33 ~]$ sudo lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 119 1 root unassigned /usr/lib/systemd/systemd ...
4026532210 net 2 3994 65535 0 /run/netns/cni-20479334-... /pause ← coredns netns
4026532326 net 3 60712 65535 1 /run/netns/cni-42afccc8-... /pause ← netshoot netns
4026532404 net 1 63257 root unassigned /usr/lib/systemd/systemd-hostnamed
| netns | NPROCS | 용도 |
|---|---|---|
4026531840 (Root) |
119 | 호스트 + hostNetwork 파드 (aws-node, kube-proxy) |
4026532210 |
2 | coredns 파드 (pause + coredns) |
4026532326 |
3 | netshoot 파드 (pause + network-multitool 프로세스들) |
4026532404 |
1 | systemd-hostnamed (시스템 서비스) |
테스트용 파드 내부 확인
netshoot 파드에 exec으로 접속하여 내부 네트워크 구성을 확인해봅시다.
$ k exec -ti $PODNAME1 -- bash
bash-5.1# ip -c addr
3: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001
inet 192.168.1.201/32 scope global eth0 ← /32 단일 IP 할당
bash-5.1# ip -c route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
bash-5.1# cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local ap-northeast-2.compute.internal
nameserver 10.100.0.10 ← coredns Service ClusterIP
options ndots:5
각 파드의 IP와 인터페이스를 정리하면:
| 파드 | 노드 | 파드 IP | 인터페이스 |
|---|---|---|---|
| netshoot-pod-..5wqnl | Node 2 (192.168.1.58) | 192.168.1.201/32 |
eth0@if5 |
| netshoot-pod-..bzvd8 | Node 1 (192.168.4.44) | 192.168.6.254/32 |
eth0@if3 |
| netshoot-pod-..nd2vz | Node 3 (192.168.9.33) | 192.168.9.201/32 |
eth0@if5 |
주목할 점:
- 파드 IP가 /32로 할당됨: 서브넷이 아닌 단일 호스트 IP
- 기본 게이트웨이가
169.254.1.1: AWS VPC CNI가 사용하는 가상 게이트웨이로, 실제 존재하는 IP가 아니라 veth pair의 호스트 측으로 트래픽을 보내기 위한 링크 로컬 주소 - DNS는
10.100.0.10(coredns Service ClusterIP)을 사용
파드 안에서 같은 노드의 coredns로 ping도 정상 동작합니다:
bash-5.1# ping -c 1 192.168.2.141
64 bytes from 192.168.2.141: icmp_seq=1 ttl=126 time=0.075 ms
노드 간 파드 통신 살펴보기
그럼 이어서 파드간 통신 시 tcpdump 내용을 확인하고 통신 과정을 알아봅시다. AWS VPC CNI는 별도의 오버레이(overlay) 통신 없이, VPC Native 통신이 가능합니다.
아래 과정을 디버깅해보도록 합시다.
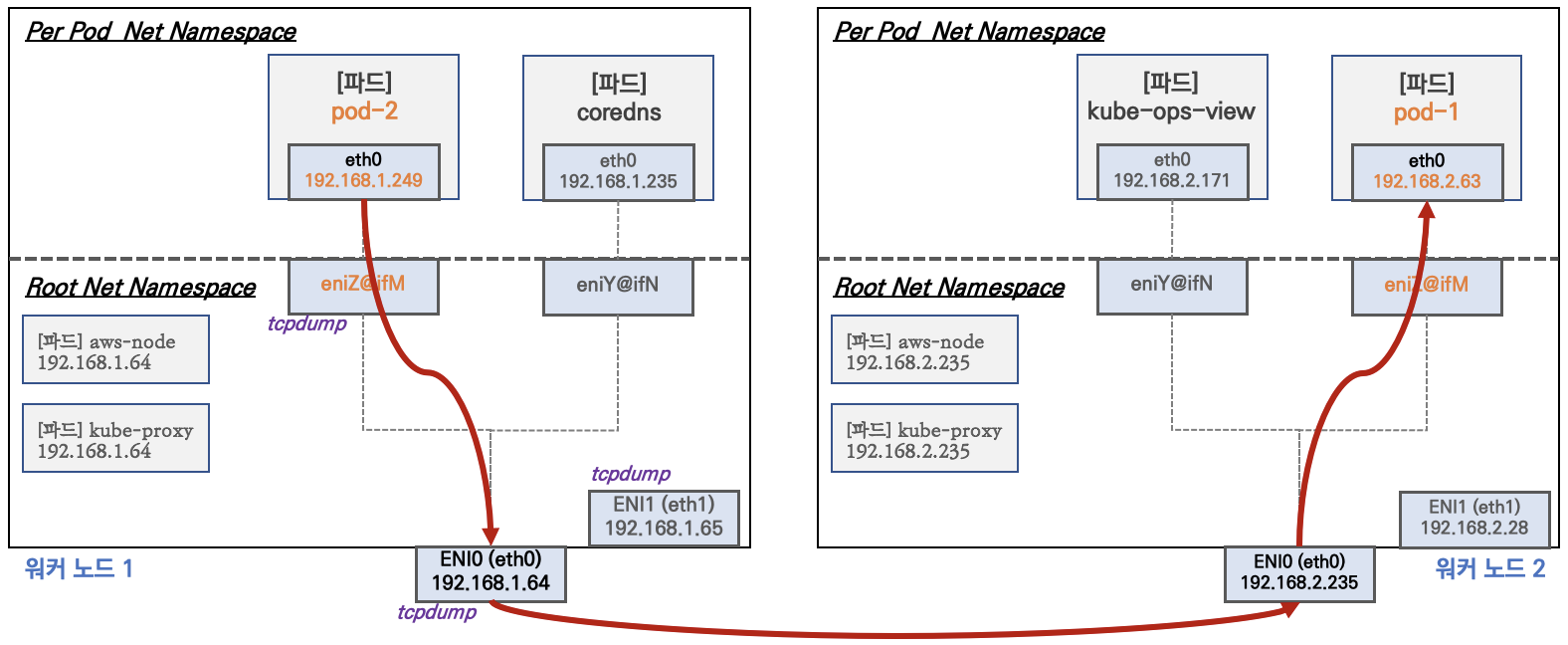

파드 간 통신 살펴보기
파드1(Node 2, 192.168.1.201)에서 파드2(Node 1, 192.168.6.254)로 ping, HTTP, HTTPS 통신을 테스트해봅시다. 서로 다른 노드에 있는 파드끼리의 통신입니다.
# ping 테스트 - 다른 노드의 파드로 직접 통신
$ kubectl exec -it $PODNAME1 -- ping -c 2 $PODIP2
PING 192.168.6.254 (192.168.6.254) 56(84) bytes of data.
64 bytes from 192.168.6.254: icmp_seq=1 ttl=125 time=1.46 ms
64 bytes from 192.168.6.254: icmp_seq=2 ttl=125 time=0.880 ms
--- 2 packets transmitted, 2 received, 0% packet loss
# HTTP 통신 - 파드2의 nginx 응답 확인
$ kubectl exec -it $PODNAME1 -- curl -s http://$PODIP2
Praqma Network MultiTool (with NGINX) - netshoot-pod-64fbf7fb5-bzvd8 - 192.168.6.254 - HTTP: 80 , HTTPS: 443
...
# HTTPS 통신
$ kubectl exec -it $PODNAME1 -- curl -sk https://$PODIP2
Praqma Network MultiTool (with NGINX) - netshoot-pod-64fbf7fb5-bzvd8 - 192.168.6.254 - HTTP: 80 , HTTPS: 443
...
마찬가지로, 파드2에서 파드3, 파드3에서 파드1로 통신도 잘 됩니다.
$ kubectl exec -it $PODNAME2 -- ping -c 2 $PODIP3
PING 192.168.9.201 (192.168.9.201) 56(84) bytes of data.
64 bytes from 192.168.9.201: icmp_seq=1 ttl=125 time=1.70 ms
64 bytes from 192.168.9.201: icmp_seq=2 ttl=125 time=1.37 ms
--- 192.168.9.201 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 1.370/1.537/1.704/0.167 ms
$ kubectl exec -it $PODNAME3 -- ping -c 2 $PODIP1
PING 192.168.1.201 (192.168.1.201) 56(84) bytes of data.
64 bytes from 192.168.1.201: icmp_seq=1 ttl=125 time=1.59 ms
64 bytes from 192.168.1.201: icmp_seq=2 ttl=125 time=1.09 ms
--- 192.168.1.201 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 1.090/1.338/1.586/0.248 ms
VPC CNI 덕분에 오버레이 없이 VPC 네이티브 라우팅으로 다른 노드의 파드에 직접 통신할 수 있습니다. 파드 IP가 VPC 서브넷의 실제 IP이므로, VPC 라우팅 테이블이 알아서 올바른 노드로 패킷을 전달합니다.
tcpdump로 패킷 경로 추적
파드1 → 파드2 ping 중에 Node 2(파드1이 있는 노드)에서 tcpdump를 잡아보면, 패킷이 어떤 인터페이스를 거치는지 확인할 수 있습니다.
-i any: 모든 인터페이스에서 캡처:
[ec2-user@ip-192-168-1-58 ~]$ sudo tcpdump -i any -nn icmp
# 요청: 파드 veth(enid8dd5b67408) → Primary ENI(ens5) 로 나감
12:04:02.757896 enid8dd5b67408 In IP 192.168.1.201 > 192.168.6.254: ICMP echo request
12:04:02.757944 ens5 Out IP 192.168.1.201 > 192.168.6.254: ICMP echo request
# 응답: Primary ENI(ens5) → 파드 veth(enid8dd5b67408) 로 들어옴
12:04:02.758663 ens5 In IP 192.168.6.254 > 192.168.1.201: ICMP echo reply
12:04:02.758711 enid8dd5b67408 Out IP 192.168.6.254 > 192.168.1.201: ICMP echo reply
패킷 경로가 명확하게 보입니다: 파드(veth) → ens5(Primary ENI) → VPC → 상대 노드. IP 변환(NAT) 없이 파드 IP 그대로 통신하는 것이 핵심입니다.
인터페이스별로 개별 캡처하면:
| 인터페이스 | 캡처 결과 | 이유 |
|---|---|---|
enid8dd5b67408 (netshoot veth) |
캡처됨 | 파드의 트래픽이 여기서 출발/도착 |
ens5 (Primary ENI) |
캡처됨 | VPC로 나가는 실제 네트워크 인터페이스 |
ens6 (Secondary ENI) |
캡처 안 됨 | 웜 풀용 ENI - 트래픽 라우팅에 사용되지 않음 |
eniaa9a601f849 (coredns veth) |
캡처 안 됨 | coredns 파드와 무관한 트래픽 |
라우팅 정책 데이터베이스 확인
ip rule로 노드의 라우팅 정책(RPDB)을 확인하면, VPC CNI가 어떻게 파드 트래픽을 라우팅하는지 볼 수 있습니다.
[ec2-user@ip-192-168-4-44 ~]$ ip rule
0: from all lookup local
512: from all to 192.168.6.254 lookup main ← 파드 IP 대상 트래픽 → main 테이블
1024: from all fwmark 0x80/0x80 lookup main ← CONNMARK된 외부 응답 → main 테이블
32765: from 192.168.7.40 lookup 2 ← Secondary ENI 출발 트래픽 → table 2
32766: from all lookup main
32767: from all lookup default
| 우선순위 | 규칙 | 의미 |
|---|---|---|
| 0 | from all lookup local |
로컬 주소(127.0.0.1, 노드 IP) 확인 |
| 512 | to 192.168.6.254 lookup main |
파드 IP로 가는 트래픽은 main 테이블 사용 (veth로 전달) |
| 1024 | fwmark 0x80/0x80 lookup main |
AWS-CONNMARK-CHAIN으로 마킹된 패킷 → main 테이블 |
| 32765 | from 192.168.7.40 lookup 2 |
Secondary ENI IP에서 출발하는 트래픽 → 별도 table 2 |
각 라우팅 테이블의 내용도 확인해보면:
# main 테이블 - 파드 트래픽은 여기서 veth pair로 전달
$ ip route show table main
default via 192.168.4.1 dev ens5
192.168.4.0/22 dev ens5 proto kernel scope link src 192.168.4.44
192.168.6.254 dev eniacae5529058 scope link ← 파드 IP → veth pair
# table 2 - Secondary ENI 전용 라우팅 (ens6)
$ ip route show table 2
default via 192.168.4.1 dev ens6
192.168.4.1 dev ens6 scope link
AWS VPC는 ENI별로 출발지 IP 검사(소스/대상 확인)를 합니다. Secondary ENI(ens6, IP 192.168.7.40)에서 출발하는 패킷은 반드시 ens6을 통해 나가야 합니다.
만약 ens5로 나가면 출발지 IP가 ens5의 것이 아니므로 VPC가 패킷을 드롭합니다. 그래서 from 192.168.7.40 lookup 2로 별도 테이블을 타게 한 것입니다.
파드에서 외부 통신
파드에서 외부로 통신해보기
파드에서 VPC 외부(인터넷)로 통신이 되는지 확인해봅시다. 앞서 iptables에서 본 AWS-SNAT-CHAIN-0이 여기서 동작합니다. VPC 외부로 나가는 트래픽은 노드 IP로 SNAT됩니다.
$ kubectl exec -it $PODNAME1 -- ping -c 1 www.google.com
PING www.google.com (142.251.155.119) 56(84) bytes of data.
64 bytes from 142.251.155.119: icmp_seq=1 ttl=107 time=23.3 ms
--- 1 packets transmitted, 1 received, 0% packet loss
$ kubectl exec -it $PODNAME1 -- ping -c 1 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=106 time=28.8 ms
--- 1 packets transmitted, 1 received, 0% packet loss
외부 통신이 정상적으로 동작합니다. 이 과정에서 실제로 SNAT이 일어나는지 확인하려면, 파드에서 ping을 보내는 동안 워커 노드에서 tcpdump를 잡아보면 됩니다:
-i any로 잡으면 veth pair(파드 IP)에서 출발한 패킷이 ens5(노드 IP)로 SNAT되어 나가는 것을 모두 볼 수 있고, -i ens5로 잡으면 SNAT 후의 패킷만 확인할 수 있습니다.
# 터미널 1: 파드에서 외부로 ping (계속 보내기)
kubectl exec -it $PODNAME1 -- ping -i 0.1 8.8.8.8
# 터미널 2: 해당 노드에 SSH 접속 후 tcpdump
sudo tcpdump -i any -nn icmp # 모든 인터페이스에서 ICMP 패킷 캡처
sudo tcpdump -i ens5 -nn icmp # Primary ENI에서만 캡처 (SNAT된 패킷 확인)
EC2에서 공인 IP를 확인해보고, 외부로 호출하는 IP 중 날씨를 보는 API가 돌아가나 잠깐 보시죠.
# 해당 명령으로 공인 IP를 확인합시다
for i in $PODNAME1 $PODNAME2 $PODNAME3; do echo ">> Pod : $i <<"; kubectl exec -it $i -- curl -s ipinfo.io/ip; echo; echo; done
# 날씨 살펴보기
kubectl exec -it $PODNAME1 -- curl -s wttr.in/seoul
패킷이 워커 노드에서 빠져나가는 과정
파드에서 외부(예: 8.8.8.8)로 ping을 보내면, 패킷이 실제로 어떤 경로를 거쳐 나가는지 워커 노드의 ip rule, ip route, iptables 를 보면서 추적해봅시다.
워커 노드 라우팅/NAT 확인
# ip rule 확인
$ ip rule
0: from all lookup local
512: from all to 192.168.6.254 lookup main
1024: from all fwmark 0x80/0x80 lookup main
32765: from 192.168.7.40 lookup 2
32766: from all lookup main
32767: from all lookup default
# 메인 라우팅 테이블 확인
$ ip route show table main
default via 192.168.4.1 dev ens5
192.168.4.0/22 dev ens5 proto kernel scope link src 192.168.4.44
192.168.6.254 dev eniacae5529058 scope link
# iptables NAT 룰 확인 - 핵심 부분만
$ sudo iptables -t nat -S | grep 'A AWS-SNAT-CHAIN'
-A AWS-SNAT-CHAIN-0 -d 192.168.0.0/16 -m comment --comment "AWS SNAT CHAIN" -j RETURN
-A AWS-SNAT-CHAIN-0 ! -o vlan+ -m addrtype ! --dst-type LOCAL -j SNAT --to-source 192.168.4.44 --random-fully
패킷 흐름 다이어그램
flowchart TD
Pod["🔵 Pod 192.168.6.254
ping 8.8.8.8"]
Veth["veth pair
eniacae5529058"]
subgraph PREROUTING ["📥 PREROUTING"]
KS1{"KUBE-SERVICES
dst = ClusterIP?"}
ACM{"AWS-CONNMARK-CHAIN-0
in: eni+
dst ∈ 192.168.0.0/16?"}
ACM_SET["CONNMARK set 0x80"]
RESTORE["CONNMARK restore
0x80 → pkt mark"]
end
subgraph ROUTING ["🧭 Routing Decision"]
IPR["ip rule 1024: fwmark 0x80 → lookup main"]
ROUTE["main table
default via 192.168.4.1 dev ens5"]
end
subgraph POSTROUTING ["📤 POSTROUTING"]
KP{"KUBE-POSTROUTING
mark 0x4000?"}
SNAT{"AWS-SNAT-CHAIN-0
dst ∈ 192.168.0.0/16?"}
SNAT_RETURN["RETURN - SNAT 안함"]
SNAT_DO["✅ SNAT
src → 192.168.4.44
--random-fully"]
end
ENS5["ens5"]
VPC["VPC Gateway 192.168.4.1"]
IGW["Internet Gateway"]
EXT["🌐 8.8.8.8"]
Pod --> Veth
Veth --> KS1
KS1 -- "NO - 외부 IP" --> ACM
KS1 -- "YES" --> DNAT_NOTE["DNAT 처리"]
ACM -- "YES - VPC 내부" --> RESTORE
ACM -- "NO - 외부" --> ACM_SET --> RESTORE
RESTORE --> IPR --> ROUTE
ROUTE --> KP
KP -- "NO - 0x4000 아님 → RETURN" --> SNAT
KP -- "YES - k8s svc 트래픽" --> MASQ["MASQUERADE"]
SNAT -- "YES - VPC 내부 목적지" --> SNAT_RETURN
SNAT -- "NO - 외부 목적지" --> SNAT_DO
SNAT_DO --> ENS5 --> VPC --> IGW --> EXT단계별 설명
1단계: PREROUTING: 패킷 마킹
파드에서 보낸 패킷이 veth pair(eniacae5529058)를 통해 노드로 진입합니다. eni+ 인터페이스에서 들어왔으므로 AWS-CONNMARK-CHAIN-0에 걸리고, 목적지가 VPC CIDR(192.168.0.0/16) 밖이면 CONNMARK 0x80이 찍힙니다.
-A AWS-CONNMARK-CHAIN-0 -d 192.168.0.0/16 -j RETURN ← VPC 내부면 패스
-A AWS-CONNMARK-CHAIN-0 -j CONNMARK --set-xmark 0x80/0x80 ← 외부면 마킹
2단계: Routing: 어디로 보낼지 결정
ip rule에서 fwmark 0x80 매칭 → main 테이블 → default via 192.168.4.1 dev ens5로 VPC 게이트웨이를 통해 나갑니다.
3단계: POSTROUTING: SNAT 적용
KUBE-POSTROUTING은 0x4000 마크가 없으니 RETURN. 이어서 AWS-SNAT-CHAIN-0에서:
-A AWS-SNAT-CHAIN-0 -d 192.168.0.0/16 -j RETURN ← VPC 내부면 SNAT 안함
-A AWS-SNAT-CHAIN-0 ! -o vlan+ ! --dst-type LOCAL -j SNAT --to-source 192.168.4.44 ← 외부면 노드 IP로 SNAT
목적지가 8.8.8.8(VPC 밖)이므로 출발지 IP가 파드 IP(192.168.6.254) → 노드 IP(192.168.4.44)로 변환됩니다.
iptables 카운터로 확인하기
실제로 SNAT이 일어나는지 카운터를 초기화하고 watch로 관찰합니다.
# 터미널 1 (워커 노드): 카운터 초기화 + watch
sudo iptables -t filter --zero; sudo iptables -t nat --zero; sudo iptables -t mangle --zero; sudo iptables -t raw --zero
watch -d 'sudo iptables -v --numeric --table nat --list AWS-SNAT-CHAIN-0; echo ; sudo iptables -v --numeric --table nat --list KUBE-POSTROUTING; echo ; sudo iptables -v --numeric --table nat --list POSTROUTING'
# 터미널 2 (작업용 EC2): ping 보내기
kubectl exec -it $PODNAME1 -- ping -i 0.1 8.8.8.8
watch에서 AWS-SNAT-CHAIN-0의 SNAT 룰 카운터가 올라가는 것을 확인할 수 있습니다. KUBE-POSTROUTING은 0x4000 마크가 아니라 RETURN에서 카운터가 올라갑니다.
conntrack으로 연결 추적 확인
SNAT된 연결의 실제 매핑을 확인할 수 있습니다.
# EC2 메타데이터 주소(169.254.169.254) 제외하고 출력
for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo conntrack -L -n |grep -v '169.254.169'; echo; done
# 출력 예시
icmp 1 28 src=192.168.6.254 dst=8.8.8.8 type=8 code=0 id=34392 src=8.8.8.8 dst=192.168.4.44 type=0 code=0 id=50705 mark=128 use=1
conntrack 결과를 읽어보면:
- 요청:
src=192.168.6.254(파드) →dst=8.8.8.8(외부) - 응답:
src=8.8.8.8→dst=192.168.4.44(노드 IP): SNAT된 주소로 응답이 돌아옴 mark=128(=0x80):AWS-CONNMARK-CHAIN에서 찍힌 마크
파드가 외부와 통신할 때는 AWS-SNAT-CHAIN-0 룰에 의해 파드 IP → 노드의 Primary ENI IP(192.168.4.44)로 SNAT되어 나갑니다. 이 덕분에 VPC의 소스/대상 확인을 통과하고, 외부에서 응답이 노드로 돌아와 다시 파드로 전달됩니다.
https://github.com/aws/amazon-vpc-cni-k8s/blob/master/misc/eni-max-pods.txt ↩︎
DNAT(Destination NAT): 패킷의 목적지 IP를 변환하는 것. 예를 들어 Service ClusterIP(
10.100.0.10:53)로 들어온 요청을 실제 파드 IP(192.168.2.141:53)로 바꿔서 전달합니다. kube-proxy가 iptables 규칙으로 이를 처리합니다. ↩︎SNAT(Source NAT): 패킷의 출발지 IP를 변환하는 것. 파드(
192.168.1.201)에서 외부(인터넷)로 나가는 패킷의 출발지를 노드 IP(192.168.1.58)로 바꿉니다. 외부에서 응답할 때 노드의 공인 IP로 돌아올 수 있도록 하기 위함입니다. VPC CNI의AWS-SNAT-CHAIN이 이를 처리합니다. ↩︎헤어핀 트래픽: 파드가 자기 자신이 속한 Service의 ClusterIP로 요청을 보내, 결국 자기 자신에게 돌아오는 경우. 출발지/도착지가 같아지므로
MASQUERADE로 출발지를 노드 IP로 바꿔야 응답이 정상 라우팅됩니다. ↩︎CANARY체인은 규칙이 비어있으며, 해당 컴포넌트가iptables규칙을 정상적으로 관리하고 있는지 확인하는 용도입니다. 이 체인이 존재하면 "해당 컴포넌트가 살아있다"는 의미입니다. ↩︎ ↩︎