[CloudNeta] EKS 워크샵 스터디 (2) - EKS Network Part 2 - CNI 설정과 Service(L4)
이번 게시글에서는 EKS 워크샵 스터디 제 2주차 내용을 작성합니다.
이 글은 3부로 나누어집니다.
- AWS VPC CNI 설정 변경 (Prefix Delegation 등)
- 노드에 파드 생성 갯수 제한
- Service & Amazon EKS 네트워킹 지원
- AWS LoadBalancer Controller & Service (L4)
이전 글에 이어서, VPC CNI 설정을 변경하고 파드 생성갯수 제한이 어떻게 달라지는지 살펴본 뒤, Service와 L4 로드밸런싱을 실습합니다.
VPC CNI 설정 바꾸기
설정을 바꾸기 전에, 현재 노드들의 네트워크 인터페이스 상태부터 확인해봅시다.
현재 노드 상태 확인
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c addr; echo; done
각 노드의 인터페이스를 정리하면:
| 노드 | ens5 (Primary ENI) | ens6 (Secondary ENI) | veth (파드) |
|---|---|---|---|
| 노드 1 (192.168.4.44) | 192.168.4.44/22 | 192.168.7.40/22 | 1개 (eniacae5529058) |
| 노드 2 (192.168.1.58) | 192.168.1.58/22 | 192.168.1.8/22 | 2개 (eniaa9a601f849, enid8dd5b67408) |
| 노드 3 (192.168.9.33) | 192.168.9.33/22 | 192.168.8.200/22 | 2개 (enidc82c4d90e6, eni499eaac00bf) |
노드 2, 3에는 veth가 2개(파드 + CoreDNS)인데, 노드 1에는 1개만 있습니다. 노드 1에는 netshoot 파드 1개만 배치되어 있고 CoreDNS가 없기 때문입니다. 파드 수에 따라 veth pair 수가 달라지는 것을 직접 확인할 수 있습니다.
라우팅 테이블도 같이 보면, 파드가 배치된 만큼 veth 경로가 추가된 것을 알 수 있습니다:
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo ip -c route; echo; done
# 노드 1 - 파드 1개 → veth 경로 1개
192.168.6.254 dev eniacae5529058 scope link
# 노드 2 - 파드 2개 → veth 경로 2개
192.168.1.201 dev enid8dd5b67408 scope link
192.168.2.141 dev eniaa9a601f849 scope link
# 노드 3 - 파드 2개 → veth 경로 2개
192.168.9.201 dev eni499eaac00bf scope link
192.168.10.233 dev enidc82c4d90e6 scope link
IPAMD로 IP 할당 상태 확인
VPC CNI의 IPAMD(IP Address Management Daemon)는 localhost:61679 에 디버깅용 API를 노출합니다. 이를 통해 ENI별 IP 풀 상태를 확인할 수 있습니다.
더 자세한 트러블슈팅 방법은 IPAMD debugging commands 문서를 참고하세요.
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i curl -s http://localhost:61679/v1/enis | jq; echo; done
노드 1의 결과를 예로 보면:
{
"TotalIPs": 10,
"AssignedIPs": 1,
"ENIs": {
"eni-098b...": {
// Primary ENI (DeviceNumber: 0)
"IsPrimary": true,
"AvailableIPv4Cidrs": {
"192.168.6.254/32": {
// ← 파드에 할당됨 (netshoot-pod)
"IPAddresses": {
"192.168.6.254": { "k8sPodName": "netshoot-pod-..." }
}
},
"192.168.4.200/32": {}, // 나머지 4개는 웜 풀에 대기 중
"192.168.4.208/32": {},
"192.168.7.32/32": {},
"192.168.7.57/32": {}
}
},
"eni-070f...": {
// Secondary ENI (DeviceNumber: 1) - 전부 미할당
"IsPrimary": false,
"AvailableIPv4Cidrs": { "192.168.4.207/32": {}, "...": {} } // 5개 IP, WARM_ENI_TARGET=1로 미리 확보
}
}
}
정리하면:
| 노드 | ENI 수 | 전체 IP | 할당된 IP | 웜 풀 IP |
|---|---|---|---|---|
| 노드 1 | 2 (Primary + Secondary) | 10 | 1 (netshoot) | 9 |
| 노드 2 | 2 (Primary + Secondary) | 10 | 2 (netshoot + CoreDNS) | 8 |
| 노드 3 | 2 (Primary + Secondary) | 10 | 2 (netshoot + CoreDNS) | 8 |
WARM_ENI_TARGET=1 설정에 의해, 파드가 Primary ENI의 보조 IP만 사용하더라도 Secondary ENI가 미리 하나 더 붙어있는 것을 확인할 수 있습니다. 이 "여유분" ENI 덕분에 새 파드가 생성될 때 ENI 할당을 기다리지 않고 바로 IP를 받을 수 있습니다.
CNI 환경변수 확인
앞서 살펴보았던 설정값을 다시 살펴봅시다.
$ k get ds aws-node -n kube-system -o json | jq '.spec.template.spec.containers[0].env'
...
{
"name": "WARM_ENI_TARGET",
"value": "1"
},
...
파일 수정
eks.tf 파일을 아래와 같이 수정합니다:
# add-on
addons = {
coredns = {
most_recent = true
}
kube-proxy = {
most_recent = true
}
vpc-cni = {
most_recent = true
before_compute = true
configuration_values = jsonencode({
env = {
#WARM_ENI_TARGET = "1" # 현재 ENI 외에 여유 ENI 1개를 항상 확보
WARM_IP_TARGET = "5" # 현재 사용 중인 IP 외에 여유 IP 5개를 항상 유지, 설정 시 WARM_ENI_TARGET 무시됨
MINIMUM_IP_TARGET = "10" # 노드 시작 시 최소 확보해야 할 IP 총량 10개
#ENABLE_PREFIX_DELEGATION = "true"
#WARM_PREFIX_TARGET = "1" # PREFIX_DELEGATION 사용 시, 1개의 여유 대역(/28) 유지
}
})
}
}
수정 후 테라폼을 재배포하면, EKS 콘솔에서 VPC CNI 애드온이 업데이트 중인 것을 확인할 수 있습니다.
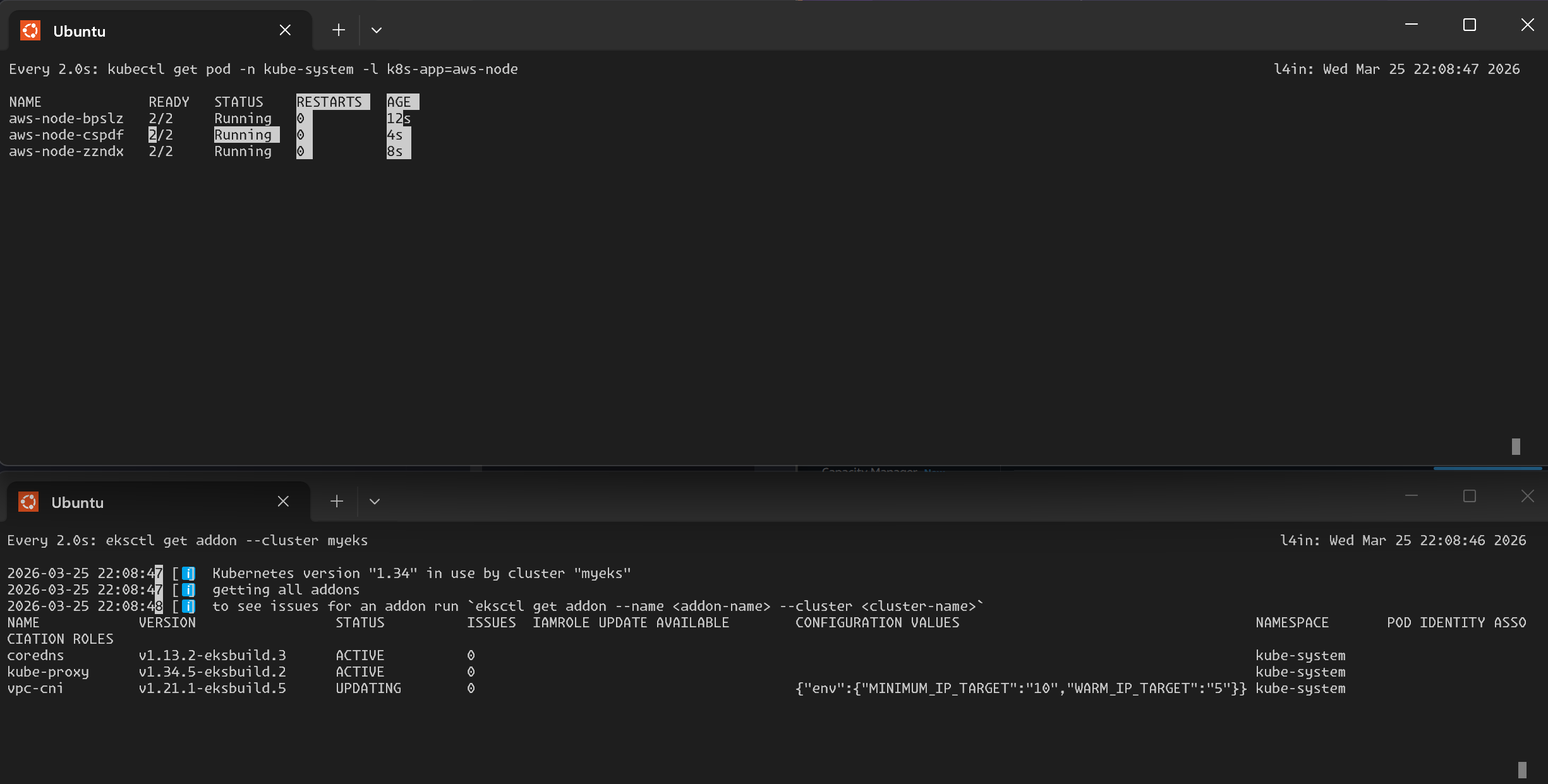
배포가 완료되면 아래와 같이 상태가 Active로 전환됩니다.
변경된 설정 확인
배포가 완료되었으니, aws-node 데몬셋이 정상적으로 재시작되었는지 확인합니다.
$ kubectl get pod -n kube-system -l k8s-app=aws-node
NAME READY STATUS RESTARTS AGE
aws-node-bpslz 2/2 Running 0 4m16s
aws-node-cspdf 2/2 Running 0 4m8s
aws-node-zzndx 2/2 Running 0 4m12s
3개 노드 모두 2/2 Running이고 AGE가 짧은 것으로 보아, 설정 변경에 따라 파드가 재생성된 것을 알 수 있습니다.
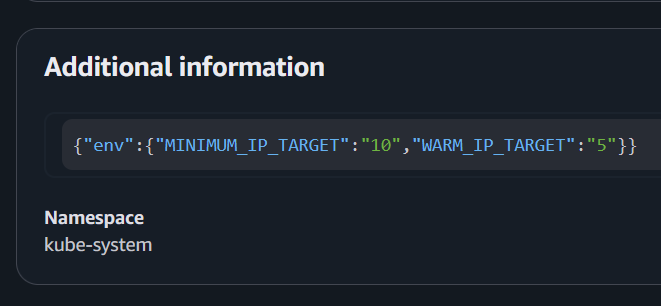
eksctl로 애드온 상태를 확인하면, CONFIGURATION VALUES에 우리가 설정한 값이 반영된 것을 볼 수 있습니다.
$ eksctl get addon --cluster myeks
NAME VERSION STATUS ISSUES CONFIGURATION VALUES
coredns v1.13.2-eksbuild.3 ACTIVE 0
kube-proxy v1.34.5-eksbuild.2 ACTIVE 0
vpc-cni v1.21.1-eksbuild.5 ACTIVE 0 {"env":{"MINIMUM_IP_TARGET":"10","WARM_IP_TARGET":"5"}}
실제 aws-node 데몬셋의 환경변수에서도 확인해봅시다.
$ kubectl describe ds aws-node -n kube-system | grep -E "WARM_IP_TARGET|MINIMUM_IP_TARGET"
MINIMUM_IP_TARGET: 10
WARM_IP_TARGET: 5
전체 환경변수 목록을 보면, 변경한 값 외에도 VPC CNI가 사용하는 주요 설정들을 한눈에 확인할 수 있습니다.
$ kubectl get ds aws-node -n kube-system -o json | jq '.spec.template.spec.containers[0].env'
주요 환경변수를 정리하면:
| 환경변수 | 값 | 설명 |
|---|---|---|
WARM_IP_TARGET |
5 |
여유 IP 5개를 항상 유지 (설정 시 WARM_ENI_TARGET 무시) |
MINIMUM_IP_TARGET |
10 |
노드 시작 시 최소 확보할 IP 총량 |
WARM_ENI_TARGET |
1 |
여유 ENI 1개 확보 (위 설정에 의해 무시됨) |
ENABLE_PREFIX_DELEGATION |
false |
Prefix Delegation 비활성화 |
AWS_VPC_ENI_MTU |
9001 |
Jumbo Frame 지원 (VPC 내부) |
AWS_VPC_K8S_CNI_EXTERNALSNAT |
false |
VPC CNI 자체 SNAT 사용 |
AWS_VPC_K8S_CNI_VETHPREFIX |
eni |
veth pair 이름 접두사 |
WARM_IP_TARGET과 WARM_ENI_TARGET의 관계
WARM_IP_TARGET이 설정되면 WARM_ENI_TARGET은 무시됩니다. 기존에는 ENI 단위로 여유분을 확보했지만, 이제는 IP 단위로 세밀하게 관리합니다. MINIMUM_IP_TARGET=10과 함께 사용하면, 노드 시작 시 최소 10개 IP를 확보하되 이후에는 항상 5개의 여유 IP를 유지하게 됩니다.
CNI 로그로 동작 확인
VPC CNI는 /var/log/aws-routed-eni/ 디렉터리에 로그를 남깁니다.
$ ssh ec2-user@$NODE1 tree /var/log/aws-routed-eni
/var/log/aws-routed-eni
├── ebpf-sdk.log
├── ipamd.log ← IP 할당/해제 관리 로그
├── network-policy-agent.log
├── egress-v6-plugin.log
└── plugin.log ← CNI 플러그인 호출 로그 (파드 생성/삭제 시)
plugin.log: 파드 생성 시 CNI가 하는 일
파드가 생성될 때 CNI 플러그인이 어떤 과정을 거치는지 확인할 수 있습니다.
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i sudo cat /var/log/aws-routed-eni/plugin.log | jq '.msg'; echo; done
노드 1의 로그를 순서대로 읽어보면:
1. "Received CNI add request: ContainerID(e864...) ... K8S_POD_NAME=netshoot-pod-64fbf7fb5-bzvd8"
→ kubelet이 CNI에 네트워크 연결 요청
2. "Received add network response from ipamd ... IPv4Addr:\"192.168.6.254\" RouteTableId:254"
→ IPAMD가 웜 풀에서 IP 할당, Primary ENI(RouteTableId=254=main)에서 나옴
3. "SetupPodNetwork: hostVethName=eniacae5529058, contVethName=eth0, ipAddr=192.168.6.254/32"
→ veth pair 생성 (호스트 측: eniacae5529058, 파드 측: eth0)
4. "Successfully setup container route, containerAddr=192.168.6.254/32, rtTable=main"
→ /32 호스트 라우트 추가 (ip route에서 봤던 그 경로)
5. "Network Policy agent for EnforceNpToPod returned Success : true"
→ 네트워크 정책 적용 완료
노드 3의 netshoot 파드는 Secondary ENI(DeviceNumber=1)에서 IP를 받았기 때문에 RouteTableId:2가 할당되고, fromContainer rule, rtTable=2 라우트가 추가로 설정됩니다. Part 1에서 봤던 ip rule의 from 192.168.7.40 lookup 2 규칙과 같은 원리입니다. 즉 VPC의 소스/대상 확인을 통과하기 위해 해당 ENI로만 패킷이 나가도록 보장합니다.
ipamd.log: IP 풀 관리와 ENI 유지 로직
IPAMD는 주기적으로 IP 풀 상태를 점검하고, 불필요한 ENI를 해제할지 결정합니다.
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i "sudo tail -20 /var/log/aws-routed-eni/ipamd.log" | jq '.msg'; echo; done
각 노드의 로그를 보면 ENI를 삭제하지 않는 이유가 명확히 나옵니다:
# 노드 1 (파드 1개)
"IP stats for Network Card 0 - total IPs: 10, assigned IPs: 1, cooldown IPs: 0"
"ENI eni-098b... cannot be deleted because it is primary"
"ENI eni-070f... cannot be deleted because it is required for WARM_IP_TARGET: 5"
# 노드 2 (파드 2개)
"IP stats for Network Card 0 - total IPs: 10, assigned IPs: 2, cooldown IPs: 0"
"ENI eni-0075... cannot be deleted because it is primary"
"ENI eni-0cbe... cannot be deleted because it is required for WARM_IP_TARGET: 5"
# 노드 3 (파드 2개)
"IP stats for Network Card 0 - total IPs: 10, assigned IPs: 2, cooldown IPs: 0"
"ENI eni-05d1... cannot be deleted because it is primary"
"ENI eni-0270... cannot be deleted because it has pods assigned"
ENI가 삭제되지 않는 이유를 정리하면:
| 노드 | Primary ENI | Secondary ENI | Secondary를 유지하는 이유 |
|---|---|---|---|
| 노드 1 | 삭제 불가 (primary) | 삭제 불가 | WARM_IP_TARGET: 5 충족에 필요 |
| 노드 2 | 삭제 불가 (primary) | 삭제 불가 | WARM_IP_TARGET: 5 충족에 필요 |
| 노드 3 | 삭제 불가 (primary) | 삭제 불가 | 파드가 할당되어 있음 (netshoot) |
노드 1, 2의 Secondary ENI는 파드가 할당되어 있지 않지만, WARM_IP_TARGET=5를 만족시키려면 Primary ENI의 여유 IP만으로는 부족하기 때문에 유지됩니다. 노드 3은 netshoot 파드가 Secondary ENI의 IP(192.168.9.201)를 직접 사용하고 있어서 삭제가 불가능합니다.
노드에 파드 생성 갯수 제한하기
이어서 파드 생성갯수를 제한하는 구성에 대해 살펴보겠습니다. 여기서는 앞서 살펴본 두가지에 대해 실습하고자 합니다. 첫째는 Secondary IPv4 addresses, 둘째는 Prefix Delegation입니다. 배포가 잘 되었는지 확인하기 위해 helm을 이용하여 kube-ops-view 를 준비하고 릴리즈 해보겠습니다.
kube-ops-view 준비하기
간단한 배포관련 도구입니다. 멀티 쿠버네티스 클러스터에도 대응하며, 여기서는 간단하기에 채택했습니다.
# kube-ops-view
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set service.main.type=NodePort,service.main.ports.http.nodePort=30000 --set env.TZ="Asia/Seoul" --namespace kube-system
# 확인
kubectl get deploy,pod,svc,ep -n kube-system -l app.kubernetes.io/instance=kube-ops-view
# kube-ops-view 접속
open "http://$NODE1:30000/#scale=1.5"
open "http://$NODE1:30000/#scale=1.3"
배포가 되면 이런 화면을 만나보실 수 있습니다.
Secondary IPv4 addresses 살펴보기
VPC CNI는 파드마다 ENI의 보조 IP를 하나씩 할당하므로, 노드에 생성할 수 있는 파드 수는 인스턴스 타입이 지원하는 ENI 수와 ENI당 IP 수에 의해 물리적으로 제한됩니다. aws-node와 kube-proxy는 호스트 네트워크를 사용하므로 이 제한에 포함되지 않아, 최대 파드 수에 2를 더합니다.
각 ENI의 Primary IP는 ENI 자체 주소로 사용되므로
-1을 합니다.+2는 호스트 네트워크를 사용하는aws-node,kube-proxy파드입니다.
예를 들어 이번 실습에 사용하는 t3.medium의 경우:
| 항목 | 값 |
|---|---|
| 최대 ENI 수 | 3 |
| ENI당 IPv4 주소 수 | 6 |
| 최대 파드 수 |
혹은 API 호출을 통해 살펴볼 수도 있습니다.
$ aws ec2 describe-instance-types --filters Name=instance-type,Values=t3.\* \
--query "InstanceTypes[].{Type: InstanceType, MaxENI: NetworkInfo.MaximumNetworkInterfaces, IPv4addr: NetworkInfo.Ipv4AddressesPerInterface}" \
--output table
--------------------------------------
| DescribeInstanceTypes |
+----------+----------+--------------+
| IPv4addr | MaxENI | Type |
+----------+----------+--------------+
| 15 | 4 | t3.2xlarge |
| 15 | 4 | t3.xlarge |
| 12 | 3 | t3.large |
| 6 | 3 | t3.medium |
| 2 | 2 | t3.nano |
| 2 | 2 | t3.micro |
| 4 | 3 | t3.small |
+----------+----------+--------------+
AWS에서 인스턴스 타입별 ENI/IP 제한을 정리한 공식 목록을 제공합니다: eni-max-pods.txt
maxPods 우선순위와 관리형/자체관리형 노드 차이에 대해서는 maxPods 결정 방법을 참고하세요.
최대 파드 생성 확인해보기
$ kubectl get pod -o=custom-columns=NAME:.metadata.name,IP:.status.podIP,NODE:.spec.nodeName
NAME IP NODE
nginx-deployment-54fc99c8d-rwwrw 192.168.9.139 ip-192-168-9-33...
nginx-deployment-54fc99c8d-s5wfj 192.168.6.215 ip-192-168-4-44...
nginx-deployment-54fc99c8d-vmjh7 192.168.2.87 ip-192-168-1-58...
이어서 스케일아웃을 단계적으로 테스트해봅시다.
kubectl scale deployment nginx-deployment --replicas=8 # 문제없음
kubectl scale deployment nginx-deployment --replicas=15 # 문제없음
kubectl scale deployment nginx-deployment --replicas=30 # 문제없음
kubectl scale deployment nginx-deployment --replicas=50 # ← 여기서 Pending 발생!
replicas를 50으로 올리자 일부 파드가 Pending 상태에 빠집니다.
$ kubectl get pods | grep Pending
nginx-deployment-54fc99c8d-29q7d 0/1 Pending 0 99s
nginx-deployment-54fc99c8d-4p9bx 0/1 Pending 0 99s
nginx-deployment-54fc99c8d-8qbqx 0/1 Pending 0 99s
... (8개 파드 Pending)
이벤트를 보면 원인이 명확합니다:
Warning FailedScheduling 0/3 nodes are available: 3 Too many pods.
3 Too many pods - 3개 노드 모두 파드 수 상한에 도달했습니다.
IPAMD로 IP 소진 확인
IPAMD API로 각 노드의 IP 풀 상태를 확인하면:
$ for i in $NODE1 $NODE2 $NODE3; do echo ">> node $i <<"; ssh ec2-user@$i curl -s http://localhost:61679/v1/enis | jq '.["0"] | {TotalIPs, AssignedIPs, ENIs: (.ENIs | to_entries | map({key: .key, IsPrimary: .value.IsPrimary, DeviceNumber: .value.DeviceNumber}))}'; echo; done
| 노드 | ENI 수 | TotalIPs | AssignedIPs | 여유 IP |
|---|---|---|---|---|
| 노드 1 | 3 (Primary + Secondary + Tertiary) | 15 | 15 | 0 |
| 노드 2 | 3 | 15 | 15 | 0 |
| 노드 3 | 3 | 15 | 15 | 0 |
3개 노드 모두 ENI 3개를 전부 사용하고 15개 IP가 전량 할당된 상태입니다. 이전에는 ENI 2개(10 IP)만 사용했는데, 파드 수가 늘어나면서 3번째 ENI(DeviceNumber=2, RouteTableID=3)가 자동으로 추가되었습니다.
t3.medium의 한계인 ENI 3개 × 보조 IP 5개 = 15개를 완전히 소진했으므로, 더 이상 파드에 줄 IP가 없습니다. 클러스터 전체로는 15 × 3 = 45개이고, 여기에 nginx + netshoot + CoreDNS + kube-ops-view가 전부 차지하고 있어 replicas=50은 불가능합니다.
t3.medium 최대 파드 수 =
3노드 합계 =
Prefix Delegation 살펴보기
Prefix Delegation은 ENI에 개별 IP 대신 /28 대역(16개 IP)을 통째로 할당하는 방식입니다. 이를 통해 동일한 ENI 수로도 훨씬 많은 파드를 수용할 수 있습니다.
사전 조건
Prefix Delegation을 사용하려면 다음 조건을 충족해야 합니다(참고 링크):
- 노드가 AWS Nitro 기반 인스턴스여야 합니다. Nitro 기반이 아닌 인스턴스는 기존처럼 개별 보조 IP만 할당하며, 파드에 할당할 수 있는 IP 수가 훨씬 적습니다.
- 서브넷에 연속된
/28CIDR 블록이 충분해야 합니다. IPv4 클러스터는/28, IPv6 클러스터는/80단위의 연속 블록이 필요합니다.
현재 사용 중인 인스턴스가 Nitro 기반인지 확인해봅시다:
$ aws ec2 describe-instance-types --instance-types t3.medium --query "InstanceTypes[].Hypervisor"
[
"nitro"
]
t3.medium은 Nitro 기반이므로 Prefix Delegation을 사용할 수 있습니다.
이를 위해 eks.tf 파일도 수정합시다. ENABLE_PREFIX_DELEGATION = true를 확인하시면 됩니다.
# add-on
addons = {
coredns = {
most_recent = true
}
kube-proxy = {
most_recent = true
}
vpc-cni = {
most_recent = true
before_compute = true
configuration_values = jsonencode({
env = {
#WARM_ENI_TARGET = "1" # 현재 ENI 외에 여유 ENI 1개를 항상 확보
#WARM_IP_TARGET = "5" # 현재 사용 중인 IP 외에 여유 IP 5개를 항상 유지, 설정 시 WARM_ENI_TARGET 무시됨
#MINIMUM_IP_TARGET = "10" # 노드 시작 시 최소 확보해야 할 IP 총량 10개
ENABLE_PREFIX_DELEGATION = "true"
#WARM_PREFIX_TARGET = "1" # PREFIX_DELEGATION 사용 시, 1개의 여유 대역(/28) 유지
}
})
}
}
기존 파드들도 위 설정 적용을 위해 재기동이 필요합니다!
kubectl rollout restart -n kube-system deployment coredns
kubectl rollout restart -n kube-system deployment kube-ops-view
최대 파드 생성 확인해보기
마찬가지로 재구성 후 다시 확인해봅시다.
$ k get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-54fc99c8d-685vs 1/1 Running 0 4s 192.168.11.81 ip-192-168-9-33.ap-northeast-2.compute.internal <none> <none>
nginx-deployment-54fc99c8d-nsqld 1/1 Running 0 4s 192.168.5.129 ip-192-168-4-44.ap-northeast-2.compute.internal <none> <none>
nginx-deployment-54fc99c8d-xbmx4 1/1 Running 0 4s 192.168.3.225 ip-192-168-1-58.ap-northeast-2.compute.internal <none> <none>
$ k get pod -o=custom-columns=NAME:.metadata.name,IP:.status.podIP
NAME IP
nginx-deployment-54fc99c8d-685vs 192.168.11.81
nginx-deployment-54fc99c8d-nsqld 192.168.5.129
nginx-deployment-54fc99c8d-xbmx4 192.168.3.225
이어서 스케일아웃을 단계적으로 테스트해봅시다.
kubectl scale deployment nginx-deployment --replicas=30 # 문제없음
kubectl scale deployment nginx-deployment --replicas=50 #
IP 갯수는 여전히 넉넉함에도 maxPods 갯수 제한으로 배포가 되지 못하는 모습입니다.
# 여전히 파드를 올리지 못합니다!
$ k events
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-qpnkt Successfully assigned default/nginx-deployment-54fc99c8d-qpnkt to ip-192-168-4-44.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-f8xld Successfully assigned default/nginx-deployment-54fc99c8d-f8xld to ip-192-168-9-33.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-vkglb Successfully assigned default/nginx-deployment-54fc99c8d-vkglb to ip-192-168-1-58.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-7mr28 Successfully assigned default/nginx-deployment-54fc99c8d-7mr28 to ip-192-168-4-44.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-lbrsm Successfully assigned default/nginx-deployment-54fc99c8d-lbrsm to ip-192-168-9-33.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-jbbtj Successfully assigned default/nginx-deployment-54fc99c8d-jbbtj to ip-192-168-1-58.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-65652 Successfully assigned default/nginx-deployment-54fc99c8d-65652 to ip-192-168-1-58.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-vmxxp Successfully assigned default/nginx-deployment-54fc99c8d-vmxxp to ip-192-168-4-44.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-tnp8z Successfully assigned default/nginx-deployment-54fc99c8d-tnp8z to ip-192-168-9-33.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-nkmj4 Successfully assigned default/nginx-deployment-54fc99c8d-nkmj4 to ip-192-168-1-58.ap-northeast-2.compute.internal
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-lg9k2 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-rff9z Successfully assigned default/nginx-deployment-54fc99c8d-rff9z to ip-192-168-9-33.ap-northeast-2.compute.internal
3m11s Normal Scheduled Pod/nginx-deployment-54fc99c8d-bh4x9 Successfully assigned default/nginx-deployment-54fc99c8d-bh4x9 to ip-192-168-4-44.ap-northeast-2.compute.internal
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-9w677 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-cx2nv 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-l98h8 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-l4m8x 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-lk2mc 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-flh88 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Warning FailedScheduling Pod/nginx-deployment-54fc99c8d-k4pc6 0/3 nodes are available: 3 Too many pods. no new claims to deallocate, preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod.
3m11s Normal Created Pod/nginx-deployment-54fc99c8d-nkmj4 Created container: nginx
3m11s Normal Created Pod/nginx-deployment-54fc99c8d-bh4x9 Created container: nginx
3m11s Normal Created Pod/nginx-deployment-54fc99c8d-jbbtj Created container: nginx
3m11s Normal Started Pod/nginx-deployment-54fc99c8d-rff9z Started container nginx
3m11s Normal Started Pod/nginx-deployment-54fc99c8d-vmxxp Started container nginx
3m11s Normal Created Pod/nginx-deployment-54fc99c8d-vmxxp Created container: nginx
3m11s Normal Pulled Pod/nginx-deployment-54fc99c8d-vmxxp Container image "nginx:alpine" already present on machine
# ipamd 도 여전히 문제가 발생합니다.
$
{
"level": "debug",
"ts": "2026-03-25T14:23:27.705Z",
"caller": "ipamd/ipamd.go:1479",
"msg": "ENI eni-05d1e98a33e1a7761 cannot be deleted because it is primary"
}
{
"level": "debug",
"ts": "2026-03-25T14:23:32.706Z",
"caller": "ipamd/ipamd.go:765",
"msg": "IP stats for Network Card 0 - total IPs: 32, assigned IPs: 15, cooldown IPs: 0"
}
{
"level": "debug",
"ts": "2026-03-25T14:23:32.706Z",
"caller": "ipamd/ipamd.go:1479",
"msg": "ENI eni-0270c1686bee6d972 cannot be deleted because it has pods assigned"
}
{
"level": "debug",
"ts": "2026-03-25T14:23:32.706Z",
"caller": "ipamd/ipamd.go:1479",
"msg": "ENI eni-05d1e98a33e1a7761 cannot be deleted because it is primary"
}
강제로 kubelet을 통해 maxPods를 임시수정해봅시다.
# 기본 정보 확인
cat /etc/kubernetes/kubelet/config.json | grep maxPods
cat /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf | grep maxPods
# sed 로 변경 : 기존 17 -> 변경 40
sudo sed -i 's/"maxPods": 17/"maxPods": 50/g' /etc/kubernetes/kubelet/config.json
sudo sed -i 's/"maxPods": 17/"maxPods": 50/g' /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf
# 적용
sudo systemctl restart kubelet
이를 진행하고, 추가로 증가해봅니다. 110개부터는 안되는군요.
$ k events
32s Normal Scheduled Pod/nginx-deployment-54fc99c8d-h5zv9 Successfully assigned default/nginx-deployment-54fc99c8d-h5zv9 to ip-192-168-1-58.ap-northeast-2.compute.internal
32s Normal Scheduled Pod/nginx-deployment-54fc99c8d-748tg Successfully assigned default/nginx-deployment-54fc99c8d-748tg to ip-192-168-9-33.ap-northeast-2.compute.internal
32s Normal Scheduled Pod/nginx-deployment-54fc99c8d-hz6qc Successfully assigned default/nginx-deployment-54fc99c8d-hz6qc to ip-192-168-4-44.ap-northeast-2.compute.internal
32s Normal Scheduled Pod/nginx-deployment-54fc99c8d-5f6qv Successfully assigned default/nginx-deployment-54fc99c8d-5f6qv to ip-192-168-1-58.ap-northeast-2.compute.internal
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-5f6qv Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "8fd9c2d8a86537da6eb83056dfff61a55c7076b9e3b0c32bc7a36b9ea112626b": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-r2jq8 Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "1d6325a03385173bbcdbbafb18eb0c37ecb5d0ba11587f9efc740fa6ebb57ff4": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Normal Started Pod/nginx-deployment-54fc99c8d-c224v Started container nginx
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-gfv8w Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "1fc6a78c8a8059274af6d736c56315dc9e5fd95fb5ef27d68a44097cc7b54657": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-89jkv Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "5ad63c83929aee252f131f7f82f345b724ef6384ba5a6729ee7b20b982d379aa": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-748tg Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "92e32a4abb534053e57ff73d46afb4d66322fe284bb07c82dacd9dbada60694c": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Normal Created Pod/nginx-deployment-54fc99c8d-c224v Created container: nginx
32s Normal Pulled Pod/nginx-deployment-54fc99c8d-c224v Container image "nginx:alpine" already present on machine
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-n7f72 Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "85f72d9f38d9d936c429881b2e3bdc1990a527de0c48f3b556564c089d126a56": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Normal Created Pod/nginx-deployment-54fc99c8d-dxntd Created container: nginx
32s Normal Pulled Pod/nginx-deployment-54fc99c8d-9grtq Container image "nginx:alpine" already present on machine
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-5df7h Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "16caed006dfaf73b4ddd30cffe34656340dd2965957119b8d4a8dfcef1991bb6": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-scq6x Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "1a8c64e876e16adcfd1f950e726e483f27096b175e8073cb1d64e9121c6507dd": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Normal Started Pod/nginx-deployment-54fc99c8d-dxntd Started container nginx
32s Normal Created Pod/nginx-deployment-54fc99c8d-9grtq Created container: nginx
32s Normal Pulled Pod/nginx-deployment-54fc99c8d-dxntd Container image "nginx:alpine" already present on machine
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-frnj2 Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "c7fabcea376623217f6379e5e8256764b9ad4669a4255d699a58101697feaec7": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-glsqk Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "d0700ece10ae886439eba8190266552b965a013910cd6d1231cafabbc4582f1f": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
32s Normal Started Pod/nginx-deployment-54fc99c8d-9grtq Started container nginx
32s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-fnwjr Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "b8764b780679cfa7bfb8085c5a9c63fff449716c24f88d85d9468397c243f826": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
22s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-5df7h Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "4f7daf22fdcb220c22eac2bfa059b36068fa313853bb5d4b116efeac1576398b": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
21s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-fnwjr Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "60b3dc790002becd3a590a89e7189ed4f4cbe25ee56678a156d5468ac56b2701": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
... 생략
4s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-mn4vq Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "04f203ab3e7918ffd0ca46e80d5d530d73a5e9961ad7c2a0cf6708a177386ad3": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
4s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-h5zv9 Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "b722fac3259ba917699afb41d9a079db0a0172b30c0631d922c648fd1e75edf6": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
3s Warning FailedCreatePodSandBox Pod/nginx-deployment-54fc99c8d-5f6qv Failed to create pod sandbox: rpc error: code = Unknown desc = failed to setup network for sandbox "c796de616b9587f18718b8e6620f2a8f7e94fe5a82dfe62c04e149d053e21b42": plugin type="aws-cni" name="aws-cni" failed (add): add cmd: failed to assign an IP address to container
로그 상으로도 IP할당이 불가하다 나오고요.
{
"level": "debug",
"ts": "2026-03-25T14:33:36.700Z",
"caller": "rpc/rpc_grpc.pb.go:135",
"msg": "DelNetworkRequest: K8S_POD_NAME:\"nginx-deployment-54fc99c8d-gfv8w\" K8S_POD_NAMESPACE:\"default\" K8S_POD_INFRA_CONTAINER_ID:\"220bba4334af3f7e21c99abb972c10a4edf630627b6331a7f5947b429983e08d\" Reason:\"PodDeleted\" ContainerID:\"220bba4334af3f7e21c99abb972c10a4edf630627b6331a7f5947b429983e08d\" IfName:\"eth0\" NetworkName:\"aws-cni\" K8S_POD_UID:\"bbe2d52d-9c6f-478d-b451-ec439f14cec6\""
}
{
"level": "debug",
"ts": "2026-03-25T14:33:36.700Z",
"caller": "ipamd/rpc_handler.go:353",
"msg": "UnassignPodIPAddress: IP address pool stats: total 33, assigned 32, sandbox aws-cni/220bba4334af3f7e21c99abb972c10a4edf630627b6331a7f5947b429983e08d/eth0"
}
{
"level": "debug",
"ts": "2026-03-25T14:33:36.700Z",
"caller": "ipamd/rpc_handler.go:353",
"msg": "UnassignPodIPAddress: Failed to find IPAM entry under full key, trying CRI-migrated version"
}
{
"level": "warn",
"ts": "2026-03-25T14:33:36.700Z",
"caller": "ipamd/rpc_handler.go:353",
"msg": "UnassignPodIPAddress: Failed to find sandbox _migrated-from-cri/220bba4334af3f7e21c99abb972c10a4edf630627b6331a7f5947b429983e08d/unknown"
}
{
"level": "info",
"ts": "2026-03-25T14:33:36.700Z",
"caller": "rpc/rpc_grpc.pb.go:135",
"msg": "Send DelNetworkReply: IPAddress: [], err: 1 error occurred:\n\t* datastore: unknown pod\n\n"
}
{
"level": "debug",
"ts": "2026-03-25T14:33:38.140Z",
"caller": "ipamd/ipamd.go:765",
"msg": "IP stats for Network Card 0 - total IPs: 32, assigned IPs: 32, cooldown IPs: 0"
}
{
"level": "debug",
"ts": "2026-03-25T14:33:38.141Z",
"caller": "ipamd/ipamd.go:1479",
"msg": "ENI eni-0270c1686bee6d972 cannot be deleted because it has pods assigned"
}
>> node REDACTED <<
{
"0": {
"TotalIPs": 33,
"AssignedIPs": 32,
...
그럼 이 상황에서 두번째 관리형 노드를 배포해보고 최대파드 생성을 체크해봅시다.
secondary node group 배포이후 110개 배포해보기
이어서 두번째 노드그룹을 배포하고, maxPods 확인 및 배포해서 테스트해봅시다.
$ eksctl get nodegroup --cluster myeks
CLUSTER NODEGROUP STATUS CREATED MIN SIZE MAX SIZE DESIRED CAPACITY INSTANCE TYPE IMAGE ID ASG NAME TYPE
myeks myeks-1nd-node-group ACTIVE 2026-03-25T08:05:45Z 2 5 3 t3.medium AL2023_x86_64_STANDARD eks-myeks-1nd-node-group-c0ce9203-93c2-9fb0-cda6-475a093fd7c1 managed
myeks myeks-2nd-node-group ACTIVE 2026-03-25T14:37:02Z 1 1 1 c5.large AL2023_x86_64_STANDARD eks-myeks-2nd-node-group-38ce92b6-b297-6e0d-3573-9f35605debe4 managed
$ aws ec2 describe-instances \
--query 'Reservations[].Instances[].{ID:InstanceId,Type:InstanceType,State:State.Name,PublicIPAdd:PublicIpAddress,PrivateIP:PrivateIpAddress,Name:Tags[?Key==`Name`]|[0].Value}' \
--output table
-------------------------------------------------------------------------------------------------------------
| DescribeInstances |
+---------------------+-----------------------+-----------------+-----------------+-----------+-------------+
| ID | Name | PrivateIP | PublicIPAdd | State | Type |
+---------------------+-----------------------+-----------------+-----------------+-----------+-------------+
| i-008dc157c0269fea5| myeks-1nd-node-group | 192.168.4.44 | 3.34.195.178 | running | t3.medium |
| i-088bdd51c689cf201| myeks-1nd-node-group | 192.168.1.58 | 43.203.200.165 | running | t3.medium |
| i-087d438a6c75b18f3| myeks-1nd-node-group | 192.168.9.33 | 3.39.239.143 | running | t3.medium |
| i-03e62d2db7d97bfe5| myeks-2nd-node-group | 192.168.11.194 | 54.180.121.152 | running | c5.large |
+---------------------+-----------------------+-----------------+-----------------+-----------+-------------+
[aws-sts] 캐시된 토큰 사용 (13분 남음)
$ kubectl get node -l tier=secondary
NAME STATUS ROLES AGE VERSION
ip-192-168-11-194.ap-northeast-2.compute.internal Ready <none> 74s v1.34.4-eks-f69f56f
[aws-sts] 캐시된 토큰 사용 (13분 남음)
maxNodes를 확인 후, 배포해봅시다.
ssh $NODE4
[ec2-user@ip-192-168-11-194 ~]$ cat /etc/kubernetes/kubelet/config.json | jq
{
...
"maxPods": 29,
...
}
[ec2-user@ip-192-168-11-194 ~]$ cat /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf
{
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"clusterDNS": [
"10.100.0.10"
],
"kind": "KubeletConfiguration",
"maxPods": 110
90개까진 못버팁니다. 이 경우 maxPods를 고치고 구동해봅시다.
cat /etc/kubernetes/kubelet/config.json | grep maxPods
cat /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf | grep maxPods
# sed 로 변경 : 기존 29 -> 변경 110
sudo sed -i 's/"maxPods": 29/"maxPods": 110/g' /etc/kubernetes/kubelet/config.json
sudo sed -i 's/"maxPods": 29/"maxPods": 110/g' /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf
# 적용
sudo systemctl restart kubelet
110개는 안되는군요. 시스템 파드가 차지하고 있기 때문에 안되는 것으로 보입니다.
to ip-192-168-11-194.ap-northeast-2.compute.internal
66s Warning FailedScheduling Pod/nginx-deployment-2-64c6845c57-xqxcc 0/4 nodes are available: 1 Too many pods, 3 node(s) didn't match Pod's node affinity/selector. no new claims to deallocate, preemption: 0/4 nodes are available: 1 No preemption victims found for incoming pod, 3 Preemption is not helpful for scheduling.
66s Normal Scheduled Pod/nginx-deployment-2-64c6845c57-7h8xl Successfully assigned default/nginx-deployment-2-64c6845c57-7h8xl to ip-192-168-11-194.ap-northeast-2.compute.internal
66s Normal Scheduled Pod/nginx-deployment-2-64c6845c57-ghkbc Successfully assigned default/nginx-deployment-2-64c6845c57-ghkbc to ip-192-168-11-194.ap-northeast-2.compute.internal
66s Normal Scheduled Pod/nginx-deployment-2-64c6845c57-29dn4 Successfully assigned default/nginx-deployment-2-64c6845c57-29dn4 to ip-192-168-11-194.ap-northeast-2.compute.internal
66s Warning FailedScheduling Pod/nginx-deployment-2-64c6845c57-2wc88 0/4 nodes are available: 1 Too many pods, 3 node(s) didn't match Pod's node affinity/selector. no new claims to deallocate, preemption: 0/4 nodes are available: 1 No preemption victims found for incoming pod, 3 Preemption is not helpful for scheduling.
그리고 돌고있는 파드의 값을 바꾸면 안되겠지요. 영속적으로 저장되는 게 아니니까요. 영속적으로 이 상태를 보존하기 위한 시도를 해보았으나 이를 실패한 기록을 공유합니다.
scale 을 0으로 내리시고 다음 작업을 이어가세요!
kubectl scale deployment nginx-deployment --replicas=0
그렇지 않으면 110개 한개치에서 evict를 자동으로 기다리다가 파드가 무한정 더 늘어납니다.
그럴 땐 당황하지 말고 위 터미널로 해결하세요.
cloudinit_pre_nodeadm 에 값 추가
이런 식으로 직접 kubelet 설정을 건들이려는 시도는 실패입니다:
# AL2023 전용 userdata 주입
cloudinit_pre_nodeadm =
{
content_type = "application/node.eks.aws"
content = <<-EOT
---
apiVersion: node.eks.aws/v1alpha1
kind: NodeConfig
spec:
kubelet:
config:
maxPods: 110
EOT
},
{
content_type = "text/x-shellscript"
content = <<-EOT
#!/bin/bash
dnf update -y
dnf install -y tree bind-utils tcpdump nvme-cli links sysstat ipset htop
EOT
}
]
cloudinit_pre_nodeadm 설정을 하나 더 추가
이런 식으로 직접 kubelet 설정을 건들이려는 시도는 실패입니다:
# AL2023 전용 userdata 주입
cloudinit_pre_nodeadm = [
{
content_type = "text/x-shellscript"
content = <<-EOT
#!/bin/bash
echo "Starting custom initialization..."
dnf update -y
dnf install -y tree bind-utils tcpdump nvme-cli links sysstat ipset htop
sudo sed -i 's/"maxPods": 29/"maxPods": 110/g' /etc/kubernetes/kubelet/config.json
sudo sed -i 's/"maxPods": 29/"maxPods": 110/g' /etc/kubernetes/kubelet/config.json.d/40-nodeadm.conf
echo "Custom initialization completed."
EOT
}
]
Service 와 Amazon EKS의 네트워킹 지원
왜 Service가 필요한가
쿠버네티스의 서비스를 설명하기에 앞서, 통상의 서버 배포를 생각해봅시다.
전통적인 서버는 Pet(반려동물)입니다. 이름을 붙이고(web-server-01), 고정 IP를 할당하고, 아프면 치료합니다. 운영자는 이 서버의 IP를 외우고, 설정 파일에 하드코딩하고, 장애가 나면 그 서버를 직접 고칩니다. 고정 IP 하나가 있어야 인터넷과 통신이 되었고, 그 IP가 곧 서버의 정체성이었죠.
쿠버네티스의 파드는 Cattle(가축)입니다. 번호를 매기고(nginx-deployment-54fc99c8d-gfv8w), 아프면 도태시키고 새로 만듭니다. 파드가 재시작되면 IP가 바뀌고, 스케일아웃하면 파드가 늘어나고, 스케일인하면 사라집니다. 개별 파드의 IP에 의존하는 것은 애초에 불가능한 구조입니다.
그러면 클라이언트는 어떤 IP로 요청을 보내야 할까요? 파드 3개가 떠 있는데, 어떤 파드로 가야 하죠? 파드가 죽고 새로 뜨면 IP가 바뀌는데, 그때마다 클라이언트 설정을 바꿔야 할까요?
이 문제를 해결하는 것이 Service입니다.
Service가 해결하는 것
Service는 휘발적인 파드 집합 앞에 **안정적인 가상 IP(ClusterIP)**와 DNS 이름을 제공합니다.
┌─────────────────────┐
│ Service │
│ ClusterIP: │
┌──────────┐ 요청 │ 10.100.23.45 │
│ 클라이언트 │ ─────────▶ │ │
│ 파드 │ │ selector: │
└──────────┘ │ app: my-app │
└──────┬──────────────┘
│
iptables DNAT (kube-proxy)
│
┌───────────────┼───────────────┐
│ │ │
▼ ▼ ▼
┌────────────┐ ┌────────────┐ ┌────────────┐
│ 파드 1 │ │ 파드 2 │ │ 파드 3 │
│ 192.168.1.201│ │ 192.168.6.254│ │ 192.168.9.201│
│ (Node 2) │ │ (Node 1) │ │ (Node 3) │
└────────────┘ └────────────┘ └────────────┘
- 파드가 죽고 새로 떠도 Service의 ClusterIP는 변하지 않습니다
- 파드가 3개에서 10개로 늘어나도 클라이언트는 같은 IP로 요청합니다
- 파드가 어느 노드에 있는지 클라이언트는 알 필요가 없습니다
즉, Service는 서비스 디스커버리(어디에 있는지 찾기)와 로드밸런싱(여러 파드에 분산)을 동시에 제공하는 추상화 계층입니다.
어떻게 구현되나? (Part 1에서 이미 봤습니다)
사실, Part 1에서 이미 Service의 구현체를 들여다본 적이 있습니다. Part 1의 iptables NAT 규칙 살펴보기에서 확인했던 체인들이 바로 그것입니다.
Service를 구현하는 컴포넌트는 세 가지이며, 각각 독립적인 역할을 맡습니다:
| 컴포넌트 | 역할 | 계층 |
|---|---|---|
| VPC CNI | 파드에 VPC 실제 IP를 할당하고, 파드 간 네이티브 라우팅을 제공. 모든 것의 기반 | L3 |
| kube-proxy | iptables 규칙으로 ClusterIP → 실제 파드 IP로 DNAT. Service의 트래픽 라우팅을 담당 | L3/L4 |
| CoreDNS | 서비스명.namespace.svc.cluster.local → ClusterIP로 DNS 해석. 서비스 디스커버리 담당 |
L7(DNS) |
이 셋의 관계를 정리하면:
1. CoreDNS: "my-service.default.svc.cluster.local 의 IP는 10.100.23.45야"
↓ (DNS 응답)
2. 클라이언트 파드가 10.100.23.45 로 요청
↓ (패킷 전송)
3. kube-proxy: iptables DNAT로 10.100.23.45 → 192.168.1.201 (실제 파드 IP)로 변환
↓ (DNAT 완료)
4. VPC CNI: 192.168.1.201은 VPC의 실제 IP → 오버레이 없이 VPC 라우팅으로 직접 도달
Part 1에서 봤던 KUBE-SVC-* → KUBE-SEP-* 체인이 3번 단계, --probability로 균등 분배하던 규칙이 바로 Service의 로드밸런싱 구현체입니다. 그리고 4번 단계에서 VPC CNI가 빛을 발합니다. DNAT 후의 목적지가 VPC 실제 IP이므로, 별도의 터널링이나 오버레이 없이 VPC 라우팅만으로 패킷이 도달합니다.
오해하기 쉬운 부분입니다. VPC CNI는 파드에 IP를 부여하고 파드 간 L3 연결을 제공하는 기반 인프라입니다. Service의 ClusterIP 라우팅(iptables DNAT)은 kube-proxy가, DNS 기반 서비스 디스커버리는 CoreDNS가 담당합니다. 이 셋은 모두 독립적인 EKS 애드온이며, 각자의 영역에서 협력하여 Service라는 추상화를 완성합니다.
kube-proxy와 프록시 모드
위에서 kube-proxy가 iptables 규칙으로 Service를 구현한다고 했는데, 좀 더 정확히 말하면 이것은 여러 프록시 모드 중 하나입니다. kube-proxy는 각 노드에서 DaemonSet으로 동작하며(Docs), Service와 Endpoints 오브젝트를 watch하다가 변경이 생기면 노드의 패킷 포워딩 규칙을 갱신합니다.
핵심은 이것입니다: kube-proxy는 직접 트래픽을 중계하지 않습니다. 커널의 패킷 필터링 계층에 규칙을 심어두고, 실제 패킷 처리는 커널이 합니다. kube-proxy가 죽어도 이미 설정된 규칙은 살아있으므로 기존 Service 통신은 계속 동작합니다(물론 규칙 갱신은 안 되지만요).
공식 문서에 따르면, kube-proxy 대신 동등한 기능을 제공하는 네트워크 플러그인(예: Cilium의 eBPF 기반 kube-proxy replacement)을 사용한다면 kube-proxy를 아예 배포하지 않아도 됩니다.
프록시 모드는 역사적으로 발전해왔으며, 현재 네 가지가 존재합니다:
1. User space 프록시 모드 (deprecated)
초기 구현체로, 현재는 사용되지 않습니다. kube-proxy 프로세스가 직접 프록시 역할을 수행했습니다.
클라이언트 → iptables(REDIRECT) → kube-proxy 프로세스(user space) → 백엔드 파드
모든 Service 트래픽이 user space의 kube-proxy 프로세스를 거쳐야 했기 때문에, kernel space ↔ user space 전환 비용이 매 패킷마다 발생했습니다. kube-proxy 프로세스가 죽으면 Service 통신 자체가 끊기는 SPOF 문제도 있었죠.
2. iptables 프록시 모드 (netfilter)
현재 EKS의 기본 모드이며, Part 1에서 확인한 모드입니다. kube-proxy가 직접 proxy 역할을 하는 대신, netfilter에 규칙만 설정하고 실제 패킷 처리는 전부 커널이 합니다.
클라이언트 → netfilter(DNAT) → 백엔드 파드
↑
kube-proxy는 여기에
규칙만 써넣는 역할
- kube-proxy는 규칙 관리자일 뿐, 데이터 경로(data path)에 있지 않습니다
- DaemonSet으로 동작하므로 죽어도 자동 재시작되고, 죽어있는 동안에도 이미 설정된 규칙으로 통신은 유지됩니다
- user space 모드 대비 훨씬 안정적이고 성능도 좋습니다
ClusterIP 접근 시 iptables 체인이 실제로 어떤 순서로 적용되는지(PREROUTING → KUBE-SERVICES → KUBE-SVC → KUBE-SEP → POSTROUTING)는 ClusterIP Service의 iptables 체인 흐름에서 상세히 정리했습니다.
Part 1에서 확인한 kube-proxy 설정을 다시 보면:
$ k describe cm -n kube-system kube-proxy-config
iptables:
masqueradeAll: false
masqueradeBit: 14
minSyncPeriod: 0s
syncPeriod: 30s # ← 30초마다 규칙 동기화
mode: "iptables" # ← 현재 사용 중인 모드
3. IPVS 프록시 모드
Linux 커널의 L4 로드밸런서인 IPVS(IP Virtual Server)를 활용하는 모드입니다. iptables 모드와 마찬가지로 netfilter hook을 기반으로 하지만, 내부 데이터 구조로 해시 테이블을 사용하여 O(1)에 가까운 룩업 성능을 제공합니다.
| 비교 항목 | iptables 모드 | IPVS 모드 |
|---|---|---|
| 데이터 구조 | 체인(선형 탐색) | 해시 테이블(O(1) 룩업) |
| 동작 위치 | kernel space | kernel space |
| 규칙 갱신 | 전체 테이블 교체 | 개별 규칙 증분 업데이트 |
| LB 알고리즘 | random(probability) | rr, wrr, lc, wlc, sh, sed, nq 등 다양 |
| 대규모 클러스터 | 성능 저하 발생 | 안정적 |
IPVS 모드는 Service 수가 1,000개를 넘어가는 대규모 클러스터에서 iptables 대비 확실한 성능 이점이 있습니다. 다만 IPVS만으로 모든 것을 처리할 수는 없어서, SNAT이나 masquerade 같은 일부 기능에는 여전히 iptables를 병행합니다.
EKS에서도 kube-proxy의 mode를 "ipvs"로 변경하여 사용할 수 있습니다. 자세한 내용은 EKS Best Practices - IPVS 문서를 참고하세요.
4. nftables 프록시 모드
iptables의 후속 API인 nftables를 사용하는 모드입니다. Linux 커널 5.13 이상이 필요합니다.
nftables는 iptables와 같은 netfilter 서브시스템 위에서 동작하지만, 더 나은 성능과 확장성을 위해 설계되었습니다. Endpoint 변경 시 규칙 갱신이 iptables 모드보다 빠르고 효율적이며, 커널 내 패킷 처리 성능도 개선됩니다(Service가 수만 개 수준일 때 체감).
5. eBPF 기반 (kube-proxy replacement)
kube-proxy 자체를 대체하는 접근입니다. Cilium 같은 CNI 플러그인이 eBPF 프로그램을 커널에 직접 로드하여, netfilter/iptables를 우회(bypass) 하고 패킷을 처리합니다.
[iptables/netfilter 기반]
패킷 → netfilter hooks → iptables/nftables/IPVS 규칙 → 라우팅 → 전달
[eBPF 기반]
패킷 → eBPF 프로그램 (TC/XDP) → 바로 전달
netfilter 스택 자체를 건너뛰므로 오버헤드가 가장 낮습니다. XDP(eXpress Data Path)와 결합하면 NIC 드라이버 레벨에서 패킷을 처리할 수도 있습니다. 다만 이 방식은 특정 CNI(Cilium 등)에 종속되며, EKS 기본 구성인 VPC CNI + kube-proxy 조합과는 별도의 선택지입니다.
정리
| 모드 | 데이터 경로 | 핵심 특징 | 비고 |
|---|---|---|---|
| kube-proxy 프로세스 | 매 패킷 kernel↔user 전환 | deprecated | |
| iptables | netfilter (iptables API) | 커널에서 처리, 선형 탐색 | EKS 기본값, 1.35+ deprecation 예정 |
| IPVS | netfilter (IPVS + iptables) | 해시 테이블, 다양한 LB 알고리즘 | 대규모 클러스터에 유리 |
| nftables | netfilter (nftables API) | iptables 후속, 더 빠른 규칙 갱신 | 커널 5.13+, Kubernetes 1.31+ stable |
| eBPF | eBPF (TC/XDP) | netfilter 우회, 최저 오버헤드 | Cilium 등 별도 CNI 필요 |
Service 타입
쿠버네티스 Service에는 네 가지 타입이 있으며, 위에서 아래로 갈수록 외부 노출 범위가 넓어집니다:
| 타입 | 접근 범위 | 동작 |
|---|---|---|
| ClusterIP | 클러스터 내부 | 가상 IP(ClusterIP)를 할당. 기본값 |
| NodePort | 클러스터 외부 (노드 IP) | ClusterIP + 모든 노드의 특정 포트(30000-32767)를 열어 외부 노출 |
| LoadBalancer | 클러스터 외부 (LB) | NodePort + 클라우드 로드밸런서(ELB/NLB)를 자동 프로비저닝 |
| ExternalName | DNS 레벨 | ClusterIP 없이, CNAME 레코드로 외부 서비스를 클러스터 내부 이름에 매핑 |
EKS 환경에서는 LoadBalancer 타입이 AWS의 로드밸런서와 연동됩니다. 그런데 이 "연동"을 누가, 어떻게 하느냐에 따라 방식이 나뉩니다.
Amazon EKS의 외부 노출 방안
쿠버네티스에서 Service를 외부에 노출하려면 결국 클러스터 밖의 로드밸런서나 프록시가 필요합니다. AWS 환경에서는 이를 구현하는 방식이 역사적으로 발전해왔으며, 크게 네 가지로 나눌 수 있습니다.
이 섹션은 아래 AWS 공식 블로그를 참고하여 작성했습니다.
1. In-tree Cloud Controller Manager
쿠버네티스에 내장된(in-tree) AWS 클라우드 프로바이더가 Service type: LoadBalancer를 감지하면, **Cloud Controller Manager(CCM)**를 통해 CLB(Classic Load Balancer) 또는 NLB(Network Load Balancer)를 자동으로 프로비저닝합니다.
Service (type: LoadBalancer)
→ Cloud Controller Manager (in-tree)
→ CLB(기본) / NLB(어노테이션 지정 시) 프로비저닝
→ NodePort를 통해 파드에 도달 (instance mode만 지원)
이 방식은 **instance mode(NodePort 경유)**만 지원합니다. 로드밸런서가 각 노드의 NodePort로 트래픽을 보내고, 노드의 iptables가 다시 파드로 DNAT합니다. 즉 트래픽이 LB → 노드 → (iptables DNAT) → 파드로 두 번 홉합니다.
별도의 컨트롤러 설치 없이 기본 제공되므로 설정이 간단하다는 장점이 있습니다. 어노테이션 수준의 세밀한 제어가 필요하지 않은 단순한 L4 노출이라면 여전히 유효한 선택지입니다.
in-tree 클라우드 프로바이더는 쿠버네티스 코어에 AWS 종속 코드가 포함되어 있어, 쿠버네티스 릴리스 주기에 맞춰야만 AWS 기능을 업데이트할 수 있었습니다. 이를 분리(out-of-tree)하여 AWS 자체 릴리스 주기로 독립시킨 것이 AWS Load Balancer Controller입니다.
2. AWS Load Balancer Controller (LBC)
AWS에서 공식으로 제공하는 out-of-tree 컨트롤러입니다. 클러스터에 별도로 설치해야 하지만, in-tree CCM 대비 훨씬 풍부한 기능을 제공합니다:
| K8s 리소스 | 프로비저닝 대상 | 계층 |
|---|---|---|
Service (type: LoadBalancer) |
NLB (Network Load Balancer) | L4 |
| Ingress | ALB (Application Load Balancer) | L7 |
LBC의 핵심 차별점은 두 가지 트래픽 모드를 지원한다는 것입니다:
Instance mode vs IP mode
[Instance mode] — in-tree CCM과 동일한 경로, LBC도 지원
NLB → Target Group (노드 IP:NodePort)
→ 노드의 iptables DNAT → 파드
[IP mode] — LBC만 가능, VPC CNI 필수
NLB → Target Group (파드 IP:Port 직접 등록)
→ 파드에 바로 도달
| 비교 항목 | Instance mode | IP mode |
|---|---|---|
| Target Group 대상 | 노드 IP + NodePort | 파드 IP + 컨테이너 Port |
| 트래픽 홉 | 2홉 (노드 → iptables → 파드) | 1홉 (NLB → 파드) |
| 클라이언트 IP 보존 | externalTrafficPolicy 설정 필요 |
기본 보존 |
| CNI 요구사항 | 제한 없음 | VPC CNI 필수 (파드 IP가 VPC 실제 IP여야 함) |
| 사용 시점 | 오버레이 CNI 사용 시, 호환성 우선 | VPC CNI 환경에서 성능/가시성 우선 |
IP mode가 가능한 이유는 Part 1에서 살펴본 VPC CNI 덕분입니다. 파드 IP가 VPC의 실제 IP이므로, NLB의 Target Group에 파드 IP를 직접 등록할 수 있습니다. 오버레이 기반 CNI에서는 파드 IP가 VPC 라우팅 테이블에 존재하지 않으므로 이 방식이 불가능합니다.
LBC는 Pod Readiness Gate를 지원합니다. 파드가 기동되어도 NLB Target Group에 등록되고 헬스체크를 통과하기 전까지는 파드를 Ready 상태로 표시하지 않습니다. 이를 통해 배포 중 트래픽 유실을 방지할 수 있습니다.
3. Ingress (L7 리버스 프록시)
Service가 L4(TCP/UDP) 수준의 로드밸런싱이라면, Ingress는 L7(HTTP/HTTPS) 수준의 라우팅을 제공합니다. 호스트명이나 경로 기반으로 여러 Service에 트래픽을 분기할 수 있습니다.
# 하나의 ALB로 여러 서비스를 라우팅
apiVersion: networking.k8s.io/v1
kind: Ingress
spec:
rules:
- host: api.example.com
http:
paths:
- path: /users
backend:
service: { name: user-svc, port: { number: 80 } }
- path: /orders
backend:
service: { name: order-svc, port: { number: 80 } }
EKS에서 AWS LBC가 Ingress 리소스를 감지하면 ALB를 프로비저닝합니다. ALB도 NLB와 마찬가지로 instance mode와 IP mode를 모두 지원합니다. 서비스 10개를 외부에 노출해야 할 때 NLB를 10개 만드는 대신, ALB 하나로 L7 라우팅하는 것이 비용과 운영 면에서 일반적입니다.
4. Gateway API
Ingress의 후속 표준으로, 더 풍부한 라우팅 기능과 역할 분리를 제공합니다.
Ingress: 하나의 리소스에 인프라 설정 + 라우팅 규칙이 혼재
Gateway API:
GatewayClass ← 인프라팀: "어떤 종류의 게이트웨이를 쓸 것인가" (ALB, NLB, ...)
Gateway ← 인프라팀: "리스너 포트, TLS 설정"
HTTPRoute ← 개발팀: "이 호스트/경로는 이 서비스로"
EKS에서는 AWS LBC가 Gateway API도 지원하며, 이 내용은 Part 3에서 다룹니다.
정리
| 방식 | 프로비저닝 | 계층 | 트래픽 모드 | 트래픽 경로 |
|---|---|---|---|---|
| In-tree CCM | CLB/NLB | L4 | instance만 | LB → NodePort → 파드 |
| AWS LBC (Service) | NLB | L4 | instance / IP | LB → 파드 IP 직접(IP) |
| AWS LBC (Ingress) | ALB | L7 | instance / IP | LB → 파드 IP 직접(IP) |
| AWS LBC (Gateway API) | ALB/NLB | L4/L7 | instance / IP | LB → 파드 IP 직접(IP) |
어떤 방식을 선택할지는 요구사항에 따라 갈립니다:
- 단순한 L4 노출, 빠른 설정 → In-tree CCM (별도 설치 불필요)
- 파드 직접 통신, 세밀한 제어 → AWS LBC + NLB IP 모드
- L7 라우팅, 여러 서비스를 하나의 LB로 → AWS LBC + Ingress(ALB)
- 인프라/개발팀 역할 분리, 풍부한 라우팅 → Gateway API
이 중 AWS LBC + NLB IP 모드(Service L4)를 이어서 실습합니다.
AWS LoadBalancer Controller (LBC) 와 Service (L4)
앞서 EKS의 외부 노출 방안을 개관했으니, 이제 실제로 AWS LBC가 NLB를 어떻게 프로비저닝하고 트래픽을 전달하는지 구체적으로 살펴봅시다.
IRSA 설정, Helm을 통한 LBC 설치, 서브넷 태깅 등 LBC 배포 과정은 1주차 - EKS 설치 및 기본 설정에서 이미 다뤘습니다. 이번 글에서는 LBC가 설치된 상태에서 NLB의 동작 방식과 트래픽 흐름에 집중합니다.
이 섹션의 다이어그램은 AWS 공식 블로그 Deploying AWS Load Balancer Controller on Amazon EKS에서 가져왔습니다.
NLB의 두 가지 트래픽 모드
AWS LBC가 Service (type: LoadBalancer)를 처리할 때 NLB를 프로비저닝하며, 트래픽을 파드까지 전달하는 경로는 instance mode와 IP mode 두 가지입니다.
Instance mode (인스턴스 유형)
NLB의 Target Group에 노드(EC2 인스턴스)의 NodePort를 등록합니다. in-tree CCM과 동일한 트래픽 경로입니다.

외부 클라이언트 → NLB → 노드(NodePort) → iptables DNAT → 파드
이 모드에서 클라이언트 IP 보존 여부는 externalTrafficPolicy 설정에 따라 달라집니다:
externalTrafficPolicy |
로드밸런싱 | 클라이언트 IP | 동작 |
|---|---|---|---|
| Cluster (기본값) | 2번 분산 (NLB → iptables) | 손실 (SNAT됨) | 노드에 도착한 트래픽을 iptables가 다른 노드의 파드로도 전달 가능. 고른 분산이지만 추가 홉 + SNAT 발생 |
| Local | 1번 분산 (NLB만) | 보존 | 노드에 도착한 트래픽을 해당 노드의 로컬 파드에만 전달. 추가 홉 없이 클라이언트 IP 유지 |
Local 모드에서의 핵심 동작:
- DNAT는 2번 발생합니다 — NLB에서 노드로 전달될 때(1차), 노드의 iptables에서 파드 IP로 변환될 때(2차)
- 클라이언트 IP는 보존됩니다 — AWS NLB는 인스턴스 타깃일 때 클라이언트 IP를 유지하고,
Local정책에서는 SNAT도 하지 않습니다 - 헬스체크 기반 최적화 — 파드가 없는 노드는 NLB 헬스체크에 실패하여 트래픽을 받지 않습니다. 불필요한 홉이 발생하지 않죠
Cluster는 분산이 고르지만 클라이언트 IP를 잃고, Local은 클라이언트 IP를 보존하지만 파드가 특정 노드에 몰려있으면 부하가 불균형해질 수 있습니다. 실무에서는 클라이언트 IP 보존이 필요한 경우(로깅, 접근 제어)에 Local을 사용합니다.
IP mode (IP 유형)
NLB의 Target Group에 파드 IP를 직접 등록합니다. AWS LBC 설치가 필수이며, in-tree CCM으로는 사용할 수 없습니다.
외부 클라이언트 → NLB → 파드 IP (VPC 네이티브, 1홉)
- NodePort를 경유하지 않으므로 추가 홉이 없고,
externalTrafficPolicy설정과 무관하게 클라이언트 IP가 기본 보존됩니다 - 이것이 가능한 이유는 VPC CNI가 파드에 VPC 실제 IP를 부여하기 때문입니다. LBC는 파드의 IP를 NLB Target Group에 직접 등록하고, NLB는 VPC 라우팅을 통해 파드에 바로 도달합니다
- LBC의 Pod Readiness Gate와 결합하면, Target Group 등록 + 헬스체크 통과 전까지 파드를
Ready로 표시하지 않아 배포 중 트래픽 유실을 방지할 수 있습니다
두 모드 비교
| 비교 항목 | Instance mode | IP mode |
|---|---|---|
| Target Group 대상 | 노드 IP + NodePort | 파드 IP + 컨테이너 Port |
| 트래픽 홉 | 2홉 (노드 → iptables → 파드) | 1홉 (NLB → 파드) |
| 클라이언트 IP 보존 | externalTrafficPolicy: Local 필요 |
기본 보존 |
| 필수 요구사항 | 없음 (in-tree CCM으로도 가능) | AWS LBC + VPC CNI |
| 레이턴시 | NodePort 경유로 상대적 높음 | 직접 통신으로 낮음 |
| 사용 시점 | 오버레이 CNI 사용 시, 호환성 우선 | VPC CNI 환경에서 성능·가시성 우선 |