[CloudNeta] EKS 워크샵 스터디 (7) - EKS 클러스터 업그레이드 Part 1 - 워크샵 시나리오 기반 인플레이스 업그레이드
이번 게시글에서는 EKS 워크샵 스터디 제 7주차 내용을 작성합니다.
이 글은 2부로 나누어집니다.
들어가며
운영 중인 쿠버네티스 클러스터를 끌어올리는 작업은 신기능 도입보다 훨씬 더 자주, 그리고 훨씬 더 조심스럽게 다뤄야 하는 일입니다. EKS는 마이너 버전을 약 14개월간만 표준 지원하고, 그 이후로는 분기 단위로 추가 비용이 붙는 확장 지원(Extended Support) 구간으로 넘어갑니다. 즉, 업그레이드는 해도 그만 안 해도 그만인 작업이 아니라 언젠가는 반드시 해야 하는, 시기를 정해 두는 작업입니다.
이번 7주차 스터디는 AWS EKS Upgrades Workshop을 베이스라인으로 삼아 진행합니다. 워크샵은 테라폼으로 프로비저닝된 1.30 베이스 클러스터에서 출발해, 컨트롤 플레인 → 데이터 플레인(매니지드 노드 그룹 / Karpenter / Fargate) → 애드온 순으로 단계적으로 끌어올리는 정공법을 다룹니다. Part 1에서는 이 워크샵의 흐름을 따라가며 인플레이스 업그레이드의 기본기를 정리하고, Part 2에서는 동일한 절차를 terraform-aws-eks-blueprints 패턴으로 재현합니다.
사전 준비와 환경 점검
워크샵 환경 접근
워크샵은 Workshop Studio에서 일회성 AWS 계정을 발급받아 진행하는 형태입니다. 콘솔 접근 후 가장 먼저 해야 할 일은 베이스라인 클러스터의 상태를 정확히 파악하는 것입니다.
# 베이스라인에서 미리 설정되어 있는 변수들
echo $CLUSTER_NAME
echo $AWS_REGION
# kubeconfig 갱신
aws eks update-kubeconfig --name $CLUSTER_NAME --region $AWS_REGION
# 컨트롤 플레인 / 노드 / 워크로드의 현재 상태
kubectl version --short
kubectl get nodes -o wide
kubectl get pods -A
워크샵 베이스라인은 보통 EKS 1.30 + 매니지드 노드 그룹 + (옵션) Karpenter / Fargate Profile의 조합입니다. 노드 버전, kubelet 버전, AMI 타입을 한번에 캡처해 두면 업그레이드 후 비교 기준으로 활용할 수 있습니다.
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.kubeletVersion}{"\t"}{.status.nodeInfo.osImage}{"\n"}{end}'
샘플 애플리케이션
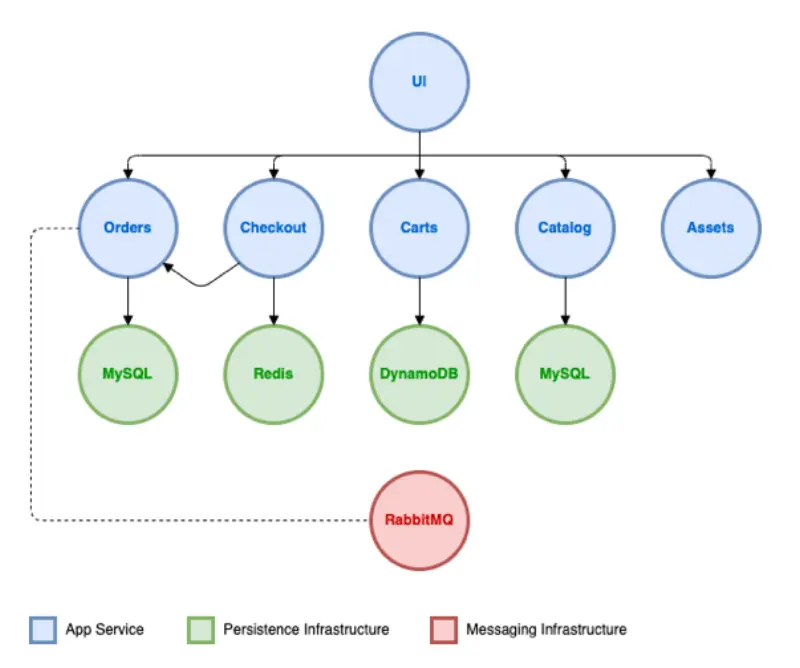
워크샵은 업그레이드 시나리오를 검증하기 위한 워크로드로 AWS가 공개한 데모 커머스 애플리케이션 aws-containers/retail-store-sample-app을 사용합니다. UI, Catalog, Carts, Checkout, Orders, Assets 6개 마이크로서비스가 폴리글랏 스택(Java/Spring Boot, Go, Node.js)으로 구현되어 있으며, 서비스별로 MySQL · Redis · DynamoDB를 데이터 스토어로 두고 Orders는 RabbitMQ로 비동기 이벤트를 흘리는 구조입니다. EKS 위에서 컨트롤 플레인과 노드를 끌어올릴 때 데이터 플레인의 다양한 종속성(스테이트풀 워크로드, 외부 메시징, 외부 DB 연동)이 골고루 영향을 받도록 설계되어 있어, 업그레이드 절차의 회귀를 한 번에 점검하기 좋은 베이스라인이 됩니다.
업그레이드 인사이트 활용
EKS는 콘솔과 API 양쪽에서 업그레이드 인사이트(Upgrade Insights)를 제공합니다. 다음 마이너로 넘어갈 때 막힐 만한 항목(Deprecated API, kubelet 인증서, EKS Add-on 버전 호환성 등)을 사전에 알려주는 점검 도구입니다.
aws eks list-insights --cluster-name $CLUSTER_NAME \
--filter "categories=UPGRADE_READINESS"
# 특정 인사이트 상세 보기
aws eks describe-insight \
--cluster-name $CLUSTER_NAME \
--id <insight-id>
콘솔에서는 클러스터 페이지 → "Upgrade insights" 탭에서 Passing / Warning / Error 상태로 분류되어 보입니다.
Error 상태의 인사이트가 단 한 건이라도 남아 있는 채로 컨트롤 플레인을 끌어올리면, 업그레이드 자체가 거절되거나 사후에 회귀를 만들 가능성이 큽니다. Warning은 운영 판단으로 넘어갈 수 있어도, Error는 모두 해소한 뒤에 시작합니다.
Deprecated API 점검
업그레이드 인사이트가 잡지 못하는 사용자 매니페스트 단의 Deprecated API는 별도 도구로 확인합니다. 워크샵에서 자주 등장하는 두 가지는 다음과 같습니다.
# 클러스터 내부에서 실제로 호출된 Deprecated API를 audit log/metrics 기반으로 검사
kubent --target-version 1.31
# 매니페스트(Helm 포함)와 클러스터 객체에서 정적/동적으로 검사
pluto detect-helm --target-versions k8s=v1.31.0
pluto detect-all-in-cluster --target-versions k8s=v1.31.0
클러스터에 이미 배포된 객체뿐 아니라, 지금은 안 쓰지만 차트/매니페스트에 남아 있는 API 버전도 함께 잡아 줍니다. CI에 pluto를 끼워두는 것이 가장 일관적인 가드레일입니다.
Pod Disruption Budget 점검
노드 롤링 단계에서 가장 자주 발이 묶이는 지점은 PDB입니다. minAvailable이 레플리카 수와 같거나 큰 PDB가 있으면 노드 드레인이 영구적으로 멈춥니다.
kubectl get pdb -A -o custom-columns=\
NS:.metadata.namespace,\
NAME:.metadata.name,\
MIN:.spec.minAvailable,\
MAX:.spec.maxUnavailable,\
ALLOWED:.status.disruptionsAllowed
ALLOWED가 0인 PDB는 노드 교체 시 항상 막힙니다. 단일 레플리카 워크로드에 무심코 minAvailable: 1로 잡혀 있는 케이스가 가장 흔한 함정입니다.
컨트롤 플레인 업그레이드
EKS 컨트롤 플레인은 AWS가 매니지드로 운영하므로, 사용자가 할 일은 버전을 한 단계 올리고 적용 결과를 검증하는 것뿐입니다.
- 마이너는 한 번에 한 단계씩만 올릴 수 있습니다. 1.30 → 1.32처럼 두 단계를 한 번에 건너뛰는 호출은 거절됩니다.
- 적용에는 평균 30~40분이 걸리며, 도중에는 컨트롤 플레인이 일시적으로 응답이 느려질 수 있습니다. 적용 시간 동안 새 객체 대량 생성을 자제합니다.
콘솔/CLI로 업그레이드 트리거
# 현재 버전 확인
aws eks describe-cluster --name $CLUSTER_NAME \
--query 'cluster.{version:version,platformVersion:platformVersion,status:status}'
# 1.30 → 1.31 업그레이드
aws eks update-cluster-version \
--name $CLUSTER_NAME \
--kubernetes-version 1.31
진행 상황은 update-id를 통해 추적합니다.
aws eks list-updates --name $CLUSTER_NAME
aws eks describe-update --name $CLUSTER_NAME --update-id <id>
업그레이드 도중에는 새 객체 생성을 가급적 자제하는 편이 안전합니다. 컨트롤 플레인이 일시적으로 응답이 느려지는 구간이 존재하기 때문입니다.
컨트롤 플레인 업그레이드 후 점검
컨트롤 플레인이 새 버전으로 올라온 시점에 노드는 여전히 이전 마이너입니다. EKS는 컨트롤 플레인과 노드 사이에 최대 한 마이너의 스큐만 허용하므로, 이 상태가 너무 오래 지속되지 않도록 합니다.
# 컨트롤 플레인은 새 버전, 노드는 이전 버전인 상태가 정상
kubectl version --short
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.nodeInfo.kubeletVersion}{"\n"}{end}'
데이터 플레인 업그레이드
워크샵은 데이터 플레인을 세 가지 레이어로 나눠 다룹니다.
- 매니지드 노드 그룹(MNG)
- Karpenter로 관리되는 노드
- Fargate Profile 기반 워크로드
각각 어떻게 새 마이너의 노드로 트래픽을 옮기는지가 다릅니다.
매니지드 노드 그룹
가장 단순한 경로는 콘솔/CLI에서 노드 그룹의 쿠버네티스 버전을 한 단계 끌어올리는 것입니다. EKS는 기본 업그레이드 동작에 따라 새 AMI로 노드를 추가 → 기존 노드를 코든/드레인 → 종료하는 순서로 롤링합니다.
aws eks update-nodegroup-version \
--cluster-name $CLUSTER_NAME \
--nodegroup-name <ng-name>
aws eks describe-nodegroup \
--cluster-name $CLUSTER_NAME \
--nodegroup-name <ng-name> \
--query 'nodegroup.{ver:version,release:releaseVersion,status:status}'
노드 그룹 버전을 명시하지 않은 경우, EKS는 컨트롤 플레인 버전과 동일한 마이너의 최신 AMI 릴리스를 선택합니다. 운영 환경에서는 그래도 release_version을 박아두고 사람이 통제하는 편이 사후 추적이 쉽습니다.
Blue/Green 노드 그룹 전환
워크샵에서 강조하는 또 다른 옵션은 새 노드 그룹을 추가로 만들어 트래픽을 옮긴 뒤 기존 노드 그룹을 제거하는 방식입니다. 같은 인플레이스 업그레이드여도, 롤백 경로가 명확하다는 점에서 운영에서 자주 채택됩니다.
# 1) 새 마이너 기반 노드 그룹 생성 (스펙은 기존과 동일하게)
aws eks create-nodegroup \
--cluster-name $CLUSTER_NAME \
--nodegroup-name green \
--kubernetes-version 1.31 \
...
# 2) 기존(blue) 노드를 코든하여 신규 파드가 더 이상 스케줄되지 않게
kubectl cordon -l eks.amazonaws.com/nodegroup=blue
# 3) 안전한 속도로 드레인
for n in $(kubectl get nodes -l eks.amazonaws.com/nodegroup=blue -o name); do
kubectl drain $n --ignore-daemonsets --delete-emptydir-data --grace-period=60
done
# 4) 검증 후 blue 노드 그룹 삭제
aws eks delete-nodegroup --cluster-name $CLUSTER_NAME --nodegroup-name blue
드레인이 PDB에 걸려 멈추면, 그 자리에서 PDB 설정과 워크로드 레플리카 수를 먼저 손봅니다. --force/--disable-eviction으로 강제 통과시키는 것은 워크로드의 가용성을 직접 깨는 행동이라, 워크샵에서도 권장되지 않습니다.
Karpenter 노드
Karpenter는 NodePool/EC2NodeClass 정의에 따라 자체적으로 노드를 갱신합니다. 1.x 버전부터는 Drift 기능이 기본으로 들어 있어, NodePool의 AMI 셀렉터나 쿠버네티스 버전이 변경되면 Karpenter가 자동으로 노드를 교체합니다.
# EC2NodeClass에서 새 마이너에 대응하는 AMI alias 사용
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiSelectorTerms:
- alias: al2023@latest # 또는 명시적인 SSM 파라미터 핀
워크샵에서는 보통 수동 드레인 없이 Drift만으로 롤링이 완결되는지를 확인하는 단계가 들어갑니다. kubectl get nodeclaim -A로 새 노드의 등장과 기존 노드의 종료를 시계열로 관찰합니다.
kubectl get nodeclaim -A
kubectl get nodes -L karpenter.sh/nodepool,kubernetes.io/arch
Fargate
Fargate 프로파일에 매칭되는 파드는 파드가 새로 생성되는 시점에 그 시점의 최신 마이너 kubelet 위에서 뜹니다. 즉, 별도 노드 업그레이드 개념 없이 파드를 한 번 재생성하면 됩니다.
kubectl rollout restart deployment -n <ns> <name>
업그레이드 직후에는 파드의 노드 버전을 다시 한 번 확인합니다.
kubectl get pods -A -o wide \
| awk 'NR==1 || $7 ~ /fargate/'
애드온 업그레이드
컨트롤 플레인 마이너가 올라가면 호환되는 애드온 버전 범위도 같이 이동합니다. 워크샵에서는 다음 네 가지가 항상 등장합니다.
- CoreDNS
- kube-proxy
- VPC CNI (
aws-node) - Amazon EBS CSI Driver
각 애드온의 호환 가능한 최신 버전을 조회한 뒤, 한 번에 하나씩 끌어올리는 것이 안전합니다.
for ADDON in coredns kube-proxy vpc-cni aws-ebs-csi-driver; do
echo "=== $ADDON ==="
aws eks describe-addon-versions \
--kubernetes-version 1.31 \
--addon-name $ADDON \
--query 'addons[].addonVersions[].addonVersion' \
--output text | tr '\t' '\n' | sort -V | tail -n 3
done
업데이트는 다음과 같이 진행합니다.
--resolve-conflicts PRESERVE는 운영 클러스터의 기본값
사용자가 손으로 수정한 컨피그(예: CoreDNS Corefile 커스텀 항목, VPC CNI 환경변수)를 EKS가 덮어쓰지 않도록 PRESERVE를 명시합니다. OVERWRITE는 신규 클러스터를 베이스라인으로 되돌릴 때만 의도적으로 선택합니다.
aws eks update-addon \
--cluster-name $CLUSTER_NAME \
--addon-name coredns \
--addon-version v1.11.3-eksbuild.2 \
--resolve-conflicts PRESERVE
업데이트 진행 상태는 describe-addon으로 확인합니다.
aws eks describe-addon \
--cluster-name $CLUSTER_NAME \
--addon-name coredns \
--query 'addon.{name:addonName,ver:addonVersion,status:status,health:health}'
status가 ACTIVE이고 health.issues가 비어 있어야 정상입니다.
사후 검증
업그레이드가 끝났다면 클러스터 자체의 상태와 워크로드의 상태를 분리해서 점검합니다.
클러스터 레벨 점검
# 컨트롤 플레인과 노드 마이너가 동일한지
kubectl version --short
kubectl get nodes -o wide
# kube-system 컴포넌트 이미지 태그가 새 버전을 가리키는지
kubectl -n kube-system get pods \
-o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].image}{"\n"}{end}'
# 비정상 파드만 추려서 확인
kubectl get pods -A --field-selector=status.phase!=Running
워크로드 레벨 점검
- HPA가 메트릭을 정상적으로 받아오는지 (
kubectl get hpa -A) - Ingress / ALB Target Group이 새 노드를 등록했는지
- 모니터링 대시보드(Prometheus, CloudWatch)에서 에러율 / 지연 시간이 회귀하지 않았는지
- 애플리케이션 측 헬스체크 / 합성 모니터링이 모두 그린인지
워크샵은 보통 여기까지를 한 사이클로 잡고, 이어서 1.31 → 1.32로 한 번 더 동일한 절차를 반복하게 합니다. 같은 절차를 두 번 반복할 수 있는지가 결국 운영에서의 자신감으로 직결되기 때문에, 이 반복 구간을 건너뛰지 않는 것을 권장합니다.
워크샵을 따라가며 느낀 포인트
- 업그레이드는 단일 이벤트가 아닌 시퀀스다. 컨트롤 플레인 → 데이터 플레인 → 애드온이라는 순서를 한 PR/티켓 단위로 쪼개서 다루면, 어느 단계에서 회귀가 났는지를 곧바로 분리해낼 수 있습니다.
- Deprecated API 점검은 코드 베이스 단에서 끝내야 한다. 클러스터 audit log만 보면 지금 이 클러스터에서는 안 쓰는데 차트 안에는 남아 있는 케이스를 놓칩니다.
pluto를 CI에 박아두는 편이 가장 안정적입니다. - Karpenter Drift는 강력하지만, 한 번에 너무 많이 흔들지 않는다. NodePool 변경 + 컨트롤 플레인 업그레이드를 동시에 적용하면 노드 롤링이 한꺼번에 일어납니다. NodePool 변경은 컨트롤 플레인 안정화 이후로 분리합니다.
- Blue/Green 노드 그룹은 롤백을 위한 보험이다. 인플레이스만으로도 충분히 끌어올릴 수 있지만, 워크샵에서 한 번 손에 익혀 두면 실제 사고 상황에서 훨씬 자신감 있게 의사결정을 내릴 수 있습니다.
Part 2에서는 여기서 익힌 절차를 콘솔/CLI 대신 테라폼 코드 변경 한 줄 + PR 단위 분리로 재현합니다. 동일한 시퀀스를 IaC 위에서 흘려 보내는 것이, 같은 클러스터를 두 번째 끌어올릴 때부터 운영 비용을 크게 줄여 주는 핵심입니다.